
 47
47
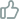 2
2
 0
0
 2023-12-19 18:08:02
2023-12-19 18:08:02
 2023-12-19
2023-12-19
近日,团队发表多模态认知与内容生成研究成果《a retrospect to multi-prompt learning across vision and language》,以暨南大学为通讯作者单位和第一作者单位被人工智能国际顶级会议(ccf a)iccv 2023接收。
人工智能顶级会议iccv是ccf a类会议,英文全称international conference on computer vision,中文全称国际计算机视觉大会,这个会议也是由ieee主办的全球最高级别学术会议之一,每两年在世界范围内召开一次,在业内具有极高的评价。iccv 2023将于2023年10月2日至6日在法国巴黎举行。本届会议共有8068篇投稿,接收率为 26.8%。
论文题目:a retrospect to multi-prompt learning across vision and language
作者:陈子良,黄鑫,官全龙(通讯作者),林倞,罗伟其
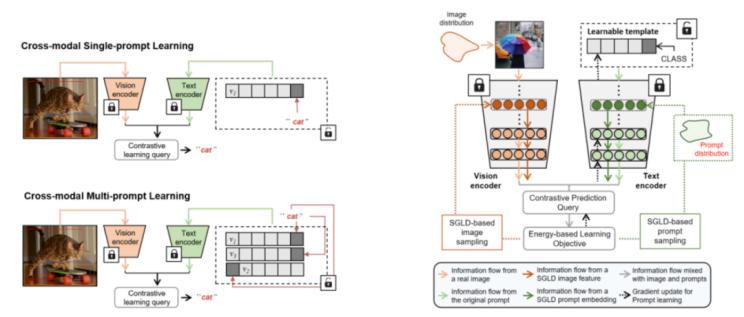
计算机视觉研究正随着视觉-语言预训练模型的出现而取得前所未有的进展。提示学习是有效访问视觉-语言预训练模型的技术钥匙,其优势在于它允许我们利用有限的资源实现对下游任务的快速模型适应。然而,现有的提示学习研究往往围绕单提示范式,甚少探究其对应的多提示学习形式以及其技术潜力。本文旨在为视觉-语言多提示学习提供一个系统性的回顾。我们从最近被发现的恒等模态间隔现象开展讨论,并以实验的方式将该现象扩展到可学习优化的提示嵌入空间。同时,我们基于恒等模态间隔现象作为理论假设,证明了跨模态不可判别性问题的存在:即给定一组跨模态对比学习模型(如clip)下,利用单个提示模板实现的提示询问结果在面对包含多个不同视觉语义概念的图像时,其提示询问结果会不可避免地出现歧义现象。跨模态不可判别性问题的存在进一步阐释了利用多提示的方式去实现提示学习的必要性。基于该观察,我们进一步提出基于能量的多提示学习(energy-based multi-prompt learning,empl),通过从由视觉-语言预训练模型隐式定义的基于能量的分布中抽取实例的方式,间接为每一个图像询问生成多个提示嵌入实现多提示学习。我们的empl方法不仅能高效节省参数使用,同时能严格地诱导出域内和域外开放词汇泛化之间的基于不确定性建模下的理论平衡。我们在mscoco数据集上验证了我们对恒等模态间隔现象对提示学习背景下的构想,同时我们提出的empl方法也在基类新类泛化,跨领域泛化以及跨数据集迁移的实验设定下取得了卓越的性能提升。
研究工作得到了国家重点研发计划(2022yfc3303603),国家自然科学基金(62077028, 62377028),粤港澳智慧教育联合重点实验室(2022lsys003)等项目的支持。






