
 510
510
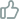 2
2
 0
0
 2023-07-18 00:06:09
2023-07-18 00:06:09
 2023-07-22
2023-07-22
2023年7月19日,香港大学曹原博士访问中国海洋大学人工智能研究院,在信息南楼a321做了题为 ”understanding the role of training algorithms in over-parameterized learning: insights from case studies” 的报告。

现代机器学习模型(比如大规模语言模型)通常包含大量参数。对于这种过参数化的模型,训练损失函数可能存在无限多个最小化者,不同的训练算法可能会收敛到不同的解。虽然这些解都可能在训练时产生零误差,但它们的预测误差可能截然不同。因此,要理解大型机器学习模型,必须理解训练算法对预测误差的影响。曹老师首先对随机梯度下降和adam优化算法之间的泛化差距进行理论解释。证明了对于某些学习问题,梯度下降可以训练一个两层卷积神经网络以获得接近零的测试误差,而adam算法只能达到常数级别的测试误差。
同时,曹老师还展示批归一化(bn)的“隐式偏差”结果。证明了当使用批归一化进行二分类问题的线性模型学习时,梯度下降会收敛到在训练数据上的“均匀边界分类器”。这个结果还可以扩展到一类简单的线性cnn。
到场的同学和老师们对这一领域和这几篇工作兴味盎然,纷纷提问和交流,讲座在热烈的讨论中结束。






