 746
746
 0
0
 2023-01-24
2023-01-24
 2023-01-24
2023-01-24
本篇学习报告基于 2020的论文《real-time denoising of volumetric path tracing for direct volume rendering》[1]。本篇论文主要由j.a. iglesias-guitian和p. mane 与b. moon等人共同完成。本篇论文提出了一种通过处理体积模型的异构噪声的加权递归最小二乘法来保留高频细节,在渲染表面模型使用图像空间降噪,使降噪器能够有效地处理体积路径追踪图像。这种方法在经典直接体渲染操作(例如相机移动、光源修改和体积传递函数修改)期间提高了的体积路径追踪图像视觉保真度和时间稳定性(如图1所示)

图1.图像在低采样率下仍然保持不错的降噪效果
1.研究背景
直接体积渲染 (direct volume rendering,简称为dvr) 使用体积路径追踪技术(volumetric path tracing,简称为vpt)代表了体积渲染算法发展的一种新趋势,该算法使用更先进的基于物理的光照模型来生成逼真的科学可视化效果。[2]蒙特卡洛路径追踪(monte carlo path tracing,简称为mcpt)通常与表面模型一起使用,但由于蒙特卡洛积分的光路在体积介质中的传输以及平滑的物体的边界极其复杂,因此它很难应用于体积模型。再者用于体数据辅助生成的几何缓冲区(geometry-buffers,简称为g-buffers)通常噪声很大,无法依赖该信息去引导图像降噪器来保留图像的细节,这使得现有的实时降噪器在对 vpt 图像进行降噪时效率较低。因此减少噪声的同时保持dvr图像序列的稳定性仍然是一个仍待解决的研究问题。在图形学领域,研究vpt的降噪一般用于离线渲染,相反的,实时交互的降噪方法主要集中在有表面模型的场景领域中,它们尚未在具有异构媒体参与的实时dvr的背景下进行探索。
2.研究方法
作者提出了实时dvr降噪框架(如图2所示),该框架建立在用于dvr的渐进式vpt之上。在每一帧,mc-dvr根据vpt和随机生成的光路估计到达每个像素的辐射量。考虑到实时渲染约束所施加的低样本数,由此产生的辐射分布通常是一个充满噪声的估计。然后使用像素重建过滤器过滤每个估计的像素颜色以获得当前帧的估计。作者提出的dvr降噪技术采用当前帧估计并更新时间,利用时间相干性指导降噪器。最后,将使用每像素线性模型预测获得最终的图像。该框架还支持使用这些预测进行空间和时间过滤。
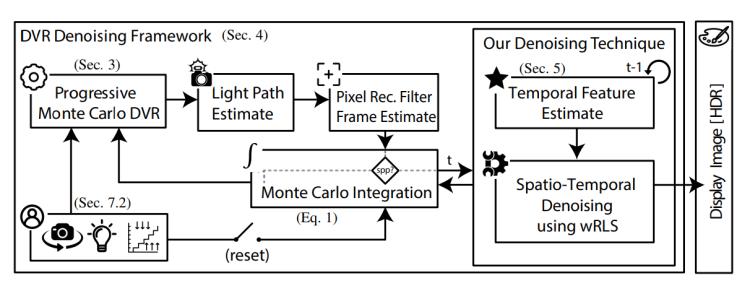
图2.实时 dvr 去噪框架
3.技术细节
(1)体积渲染积分
基于传统的蒙特卡洛体渲染方程的基础下,为了开发交互式体绘制,作者提出了一个渐进式体积路径追踪框架[3]。
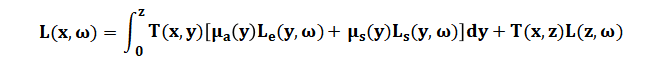
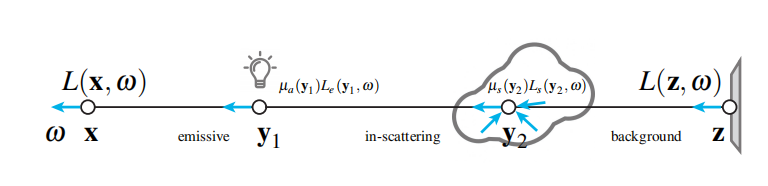
图3.光路传输图示,传输l(x,ω) 在方向ω到其射线原点x处的辐射能量。
其中![]() 和
和![]() 为y 点的吸收和散射概率,t(x,z)为两点之间光的透射率或衰减,l(z,ω)z 点沿ω方向来自背景表面发射或反射的能量。
为y 点的吸收和散射概率,t(x,z)为两点之间光的透射率或衰减,l(z,ω)z 点沿ω方向来自背景表面发射或反射的能量。
(2)vpt 线性模型的时间相干性。
时间重投影是一种利用连续帧中的时间一致性的技术,它维护着一个额外的存储空间(例如,历史缓冲区),存储着随时间累积的像素颜色。而传统的时间重投影是重投影像素颜色,[4]作者的方法是重新投影线性模型以利用时间相干性更强的实时vpt。重用线性模型比重投影方案优势在于每个像素的缓存常量值(例如,历史缓冲区)。线性回归可以预测逐渐变化的相机、光源和传递函数,而且它会立即做出反应改变着色。我们估计使用视图矩阵和每个像素的世界坐标来估计线性模型每个像素的速度vj(即光流),一旦计算出第j个像素的速度,我们就可以定义一个重投影操作π ,它获得前一帧中对应的像素坐标q为q←π (vj)。即使对于vj=0的情况,如光照或传递函数发生变化,线性模型也可以预测渐进的变化。具体如图4.所示
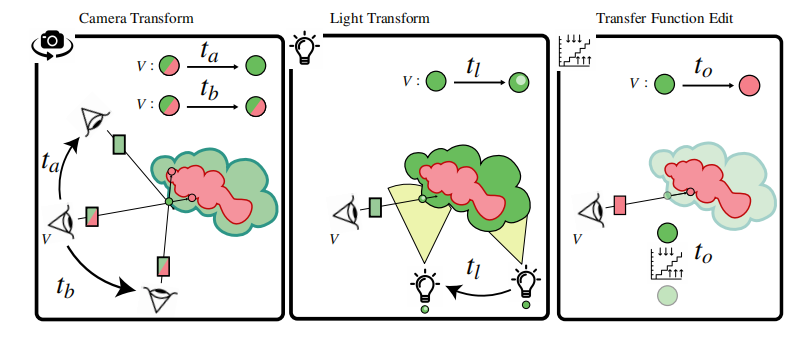
图4.体数据上的重投影效果。线性重投影模型对摄像机位移、光源修改和传递函数的变换作出反应,线性模型的自适应行为避免了触发额外的蒙特卡洛积分复位操作。
(3)加权递归最小二乘法(wrls)。
作为一项关键的技术贡献,作者提出了一种加权rls (wrls),它考虑了用少量样本生成的 dvr 图像中的异构噪声。在高频信息,wrls 将高权重分配给具有低方差的样本,将低权重分配给具有高方差的样本。特别是,为离群样本分配了非常低的权重,这些样本具有极高的方差,因此线性模型可以产生时间稳定的结果。计算权重的直接方法是利用像素颜色的样本方差,但这对于只有少数样本可用的实时场景来说无法稳健地实现。为了应对这一挑战,作者通过利用时间稳定特征来控制权重。计算权重的直接方法是利用采样像素颜色的方差,但在只有少数样本可用的情况下,这不能稳定地实现实时场景。为了应对这一挑战,作者通过利用暂时稳定的特征。明确地将权重![]() 分配给
分配给![]() ,主要计算如下公式
,主要计算如下公式
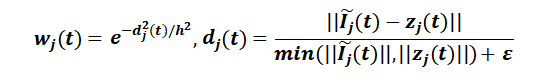
其中![]() 为在t时刻图像i的第j个像素的蒙特卡洛积分估计值,zj(t)是在t时刻像素j的特征向量,其中
为在t时刻图像i的第j个像素的蒙特卡洛积分估计值,zj(t)是在t时刻像素j的特征向量,其中![]() 是一个非常小的数字,以避免被零除,h是控制去噪之间权衡的过滤带宽偏差和方差。
是一个非常小的数字,以避免被零除,h是控制去噪之间权衡的过滤带宽偏差和方差。
如图5.显示了使用和不使用 rls 和 wrls 作者提出的时间特征的结果,结果显示,当使用了作者提出的时间特征时,都明显减少了错误。虽然两种方法都比mc估计输入明显减少了噪声,但是作者提出的方法与rls相比能很好地处理尖峰噪声如图6.所示,因为wrls能处理通过改变其权重自适应地适应异构噪声。
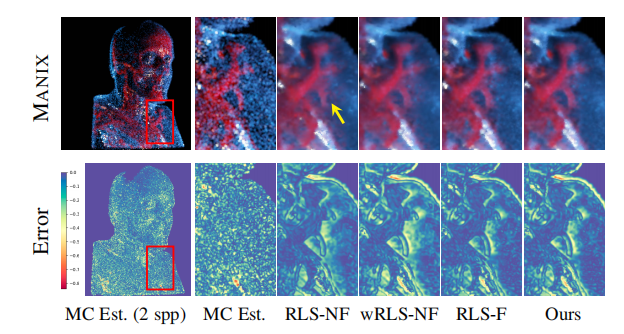
图5.加入时间特征与不加入时间特征的对比图

图6.同时加入时间特征的rls和wrls的对比图
4.实验结果
作者使用一系列实验验证了dvr去噪的性能,其中使用固定的体数据集:manix、chameleon、heloderma 和dragon(见表1)。
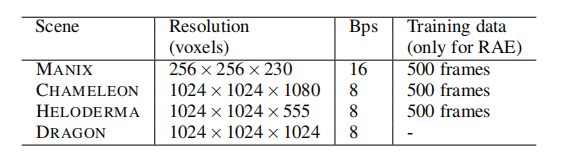
表1.实验使用的场景。
(1)dvr测评场景
对于此测试,作者使用训练时使用的相同 hdr 光探针捕获环境照亮数据集,并为围绕体数据旋转的矩形区域光设置动画。如图7(a)渲染体数据的视觉差异效果展示,图7(b)展示了变色龙场景随时间变化的psnr和lpips

图7(a).渲染体数据的视觉差异效果展示
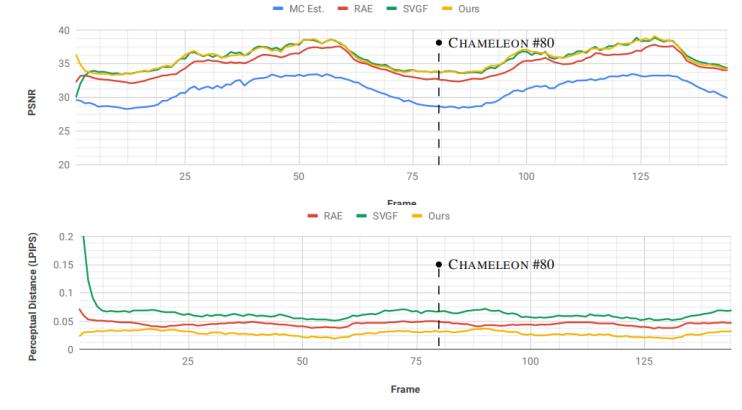
图7(b).变色龙场景随时间变化的数值精度
(2)收敛性和时间稳定性
图8显示了改变样本采样率(spp)的结果,它表明数值精度随着 spp 的增加而逐渐改善。同时作者也比较rae的数值收敛如图9所示,显示出比以前的方法更好的收敛性。例如,随着样本数量的增加,rae对噪声输入图像的改进变得更加平缓。换言之,作者的方法不断改进输入图像。

图8.在不同采样率下的结果对比
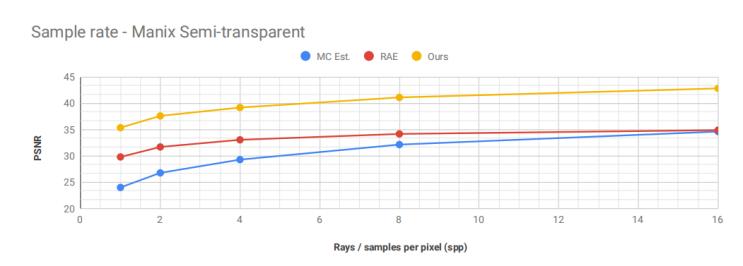
图9.在半透明manix数据集下,收敛性的对比
动画序列的时间稳定性是在交互式可视化过程中最大化用户体验的一个关键方面。相机动画对时间重投影来说是具有挑战性的场景。使用了作者提出的方法后,在实验中没有出现到强烈的过度模糊或重影,尤其是与遭受低频和中频闪烁伪影的 rae 相比时。 在图10中,作者测试了静态相机的去噪方法,但存在仅由相机光线中存在的随机抖动引起的输入时间 mc方差。作者的方法在保留体积细节的同时适当地处理尖峰噪声。
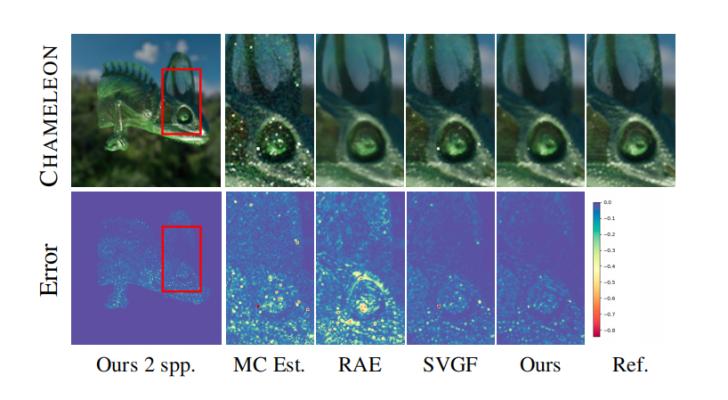
图10.在变色龙数据集上时间闪烁和异常值去除效果展示
原论文:
参考文献
撰稿人:陈志铭
审稿人:罗胜舟






