 1784
1784
 0
0
 2022-12-05
2022-12-05
 2022-12-05
2022-12-05
本篇学习报告的内容来自《learning affinity from attention: end-to-end weakly-supervised semantic segmentation with transformers》,目前该文章已经收录到cvpr2022当中。在基于图像级别标注的弱监督语义分割问题中,cnn分类模型不能正确地探索全局信息,进而导致不完全的语义区域激活。为解决这个问题,作者引入transformer结构,并探索了适合视觉transformer的初始伪标签生成方法。
语义分割的目标是为了给图像中的每个像素点分配标签,是计算机视觉的基础任务之一。传统的全监督语义分割任务大都需要非常大的带有像素级标签的数据集,成本巨大,代价高且耗时耗力。为解决这个问题,最近的一些工作提出了弱监督语义分割(wsss)的方法。目前流行的wsss方法中大部分都是采用多阶段训练框架的方法,也就是利用伪标签来训练网络。伪标签技术就是利用在已标注数据所训练的模型在未标注的数据上进行预测,根据预测结果对样本进行筛选,再次输入模型中进行训练的一个过程,具体的步骤:
这种方法由于需要训练多个网络,或者多次训练网路导致整个流程的效率低下。为了避免这个问题,许多端到端的方法被提出,但大多利用卷积神经网络,而卷积神经网络对全局特征提取以及全局特征间联系获取能力不足,从而对生成的伪标签质量产生显著的影响。
基于上述问题,作者引入transoformer结构。首先transformer的自注意力机制可以保证全局特征的提取,解决了cnn的局部性缺陷,因此能够提高初始伪标签的准确性。同时,自注意力图和像素之间的语义affinity也存在天然的一致性,而语义affinity可以被进一步用于对初始伪标签进行细化。然而,由于自然学习到的自注意力矩阵缺乏监督信息,直接将原始自注意力矩阵作为affinity信息对伪标签进行细化并不能取得令人满意的效果。故作者提出了affinity from attention(afa)模块,以初始伪标签作为监督信息指导自注意力的训练,从而学习到高质量的affinity信息,用于伪标签的改善。
1.本文提出了一种基于端到端transformer框架的带有图像级别标签弱监督语义分割框架(wsss)。据作者所了解,这是第一个用transformer去研究wsss的工作。
2.在本文中作者利用transformer的内在优点,设计了affinity from attention(afa)模块。afa从多头自注意力中学到可靠的语义affinity,并以学习到的affinity传播伪标签。
3.本文提出了一种有效的像素自适应细化(par)模块,该模块结合了局部像素的rgb和位置信息,用于标签细化。
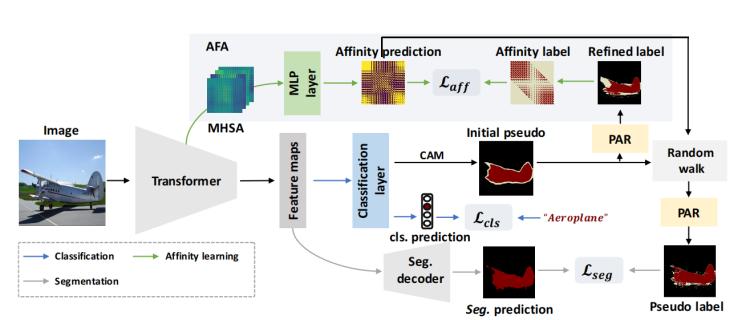
图1. 端到端wsss框架图。本文使用transformer作为基础编码器。初始伪标签由cam方法生成,然后使用提出的像素自适应细化模块(par)进行修正。在affinity学习模块(afa)中,从transformer中的多头自注意力(mhsa)生成语义affinity预测。afa使用基于细化初始伪标签的伪affinity标签进行监督。然后,利用学习到的affinity通过随机游走方法对初始伪标签进行改善。在经过par的进一步修正后,作为分割分支的监督信息。
如图1所示,作者使用transformer作为backbone。首先将输入图像分割成h * w个patch,并且经过线性层后得到相同数量的patch token。在每个transformer block当中都是用多头注意力机制(multi-head self-attention mhsa)来捕捉全局特征感知,也就是得到token之间的关系。其中,用qi,ki,vi来表示注意力中的query,key和value,其中i表示第i个头(head)。对应的注意力矩阵和输出公式分别计算为:
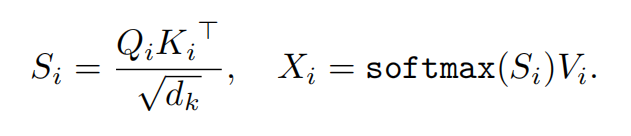
多头注意力的结果(x1~xn)会进行拼接,然后作为输入进入ffn层作为transformer block的输出x0,即
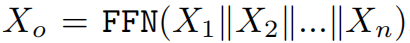
最后通过堆叠多个block,主干backbone会为后续模块生成feature maps
考虑到生成伪标签的简洁性和效率,作者使用类激活映射(class activation maps cam)来生成初始的伪标签。对于提取的特征映射f和给定的类c,通过将f中的特征映射及其对类c的影响进行加权,即分类层中的权重矩阵w,生成激活映射m。计算公式如下:
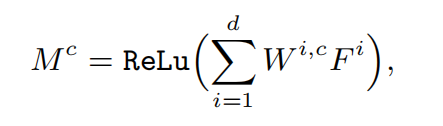
使用relu函数消除负激活值后进行归一化,在选取合适的背景阈值得到初始的伪标签。
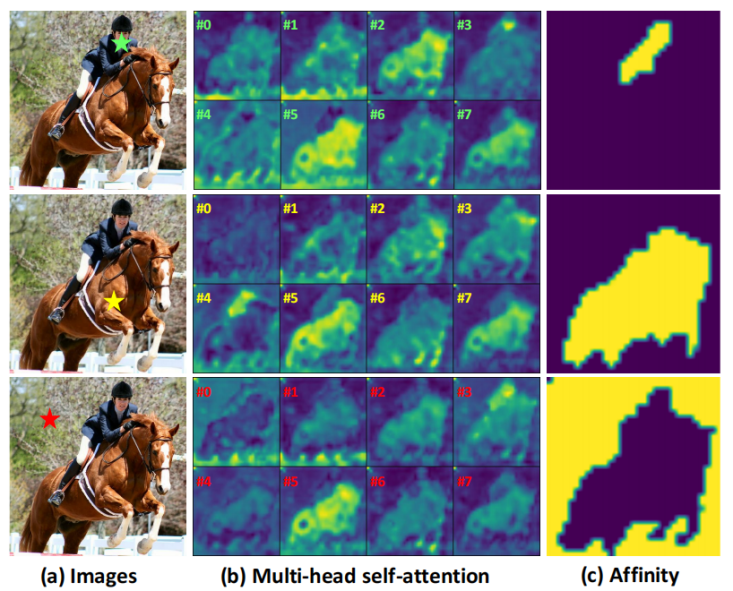
图2.视觉transformer中的多头注意力(中)及基于注意力学习到的affinity(右)
如图2所示,作者指出transformer的mhsa与语义affinity之间存在一致性,进而可以用mhsa来找到目标对象的区域。然而,由于在训练过程中没有对自注意力矩阵施加明确的约束,因此在mhsa中学习到的affinity通常是不准确的。这也意味着直接用mhsa作为affinity来细化初始labels并不能得到令人满意的效果。因此作者提出affinity from attention(afa)模块来解决这个问题。
假设transformer块的mhsa表示为s ∈ r hw×hw×n,其中hw是图像空间的大小,n是注意力头的数量。在afa模块中,作者通过线性组合多头注意力机制,即使用一个mlp层,直接生成语义affinity。然而自注意力机制是一种像素间有向的建模方式,即自注意力矩阵是不对称的,而语义affnity的关联应当是无向的。
所以,为了实现mhsa到语义affinity的转换,作者直接将s和它的转置进行相加:
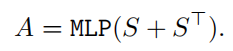
为了学习有用的语义affinity a,最重要的一步是得到一个可靠的伪affinity标签yaff并对其进行监督。为了得到可靠的伪标签,作者选取两个背景阈值将初始伪标签分为可靠的前景、背景和不确定区域。根据给定的cam m ∈ rh×w×c,构建伪标签yp的公式如下:
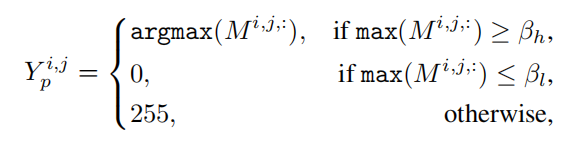
然后从yp中推导出伪affinity标签yaff。对于yp,如果(i,j)和(k,l)共享同一个语义信息,那么将它们的affinity值设为正,其他情况则为负。如果像素对在被忽略的区域内被采样,则它们的affinity也会被忽略。此外,这里只考虑像素对在同一个局部窗口的情况,而不考虑远处像素对的affinity。
利用生成的伪affinity标签yaff来监督预测的affinity a。affinity 损失公式如下:
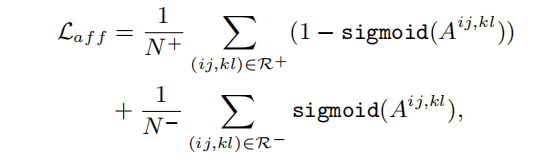
其中,r 和r-表示yaff样本正负集合,n 和n-表示r 和r-的数量。根据上式,一方面网络能从mhsa中学习到可靠的affinity关系;另一方面,由于affinity是mhsa的线性组合,上式又能保证注意力矩阵中更好的特征交互。
在得到可靠的affinity矩阵之后,我们通过随机游走算法对初始伪标签进行修正:
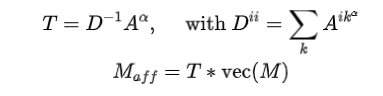
通过随机游走算法,可以对初始为标签中的高affinity区域进行激活,并抑制低affinity的错误激活区域,从而使得伪标签更好地贴合图像的语义信息。
据图1所示,伪affinity标签yaff来自于初始伪标签。然而,初始伪标签通常都是粗糙且局部不一致的,具有相似low-level的临近像素也可能不具有相同的语义。为确保局部的一致性,之前一些工作采用了crf来调整初始为标签,但是crf由于其训练效率低,所以并不是很适合端到端的网络。受pamr的启发,作者结合rgb和空间信息来定义低级的pairwise affinity并构建自己的像素自适应细化模块(par)。
首先给定的输入图像 i,对于给定位置的像素对,定义两个像素的rgb信息和位置信息的kernel:
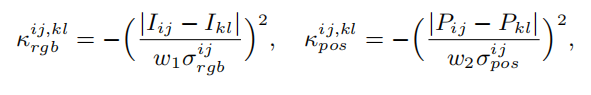
根据定义的位置和rgb信息kernel函数计算像素之间的low-level affinity值为:
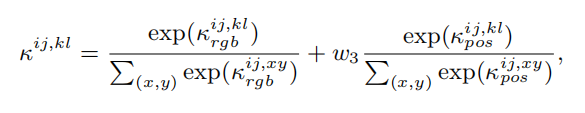
与crf中计算全局像素的low-level affinity不同,我们根据像素的8个邻居像素进行计算,该过程可以使用3x3的像素自适应卷积实现,从而能够高效的插入到端到端的训练框架中。同时为了扩大感受野,使用多个空洞卷积进行多个邻居像素信息的提取。得到像素之间的low-level affinity之后,通过多次迭代进行伪标签的修正:
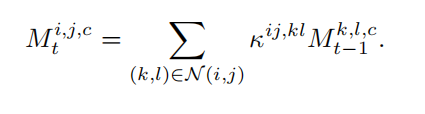
据图1所示,训练损失函数包括分类损失,分割损失和affinity损失。其中分类损失采用常见的多分类软间隔损失,分割损失则采用交叉熵损失。总损失计算公式如下:
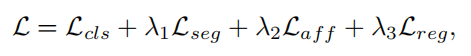
本文作者使用的数据集是pascal voc2012和ms coco 2014数据集,这两个数据集的训练集都是仅用图像级标签进行标注,且作者使用mean intersection-over-union (miou)作为评估标准。在网络结构方面,作者使用比vanila vit更加友好的mix transformer作为backbone。对于分割解码器,作者使用mlp解码头,它将多层次的特征图和简单的mlp层融合进行预测。主干参数用imagenet-1k预训练的权值初始化,其他参数用随机初始化。
在cnn中,分类层前的池化方法对cam生成效果有显著的影响,作者实验了对transformer结构合适的池化方式,并且发现相比于cnn中的全剧平均池化(gap),transformer结构全局最大池化(gmp)能够得到更好的类别激活图.
表1.top-k池化对生成的类别激活图的影响
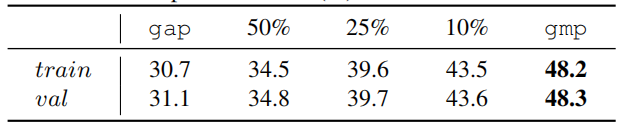
表2.消融实验下加入各模块的miou
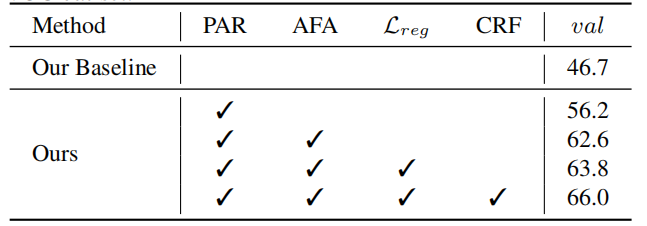
表2展示了作者提出模块的具体效果。我们可以看到在只有baseline的情况下,val集达到了46.7%。而所提出的par和afa进一步显著提高了miou,分别提高了56.2%和62.6%,此外在改进了损失计算公式后该框架达到了63.8%的miou。crf后处理进一步带来了2.2%的miou提升,将最终的性能提高到66.0%的miou。简而言之,作者提出的模块是非常有效的。
表3. afa在不同模块下的伪标签的miou
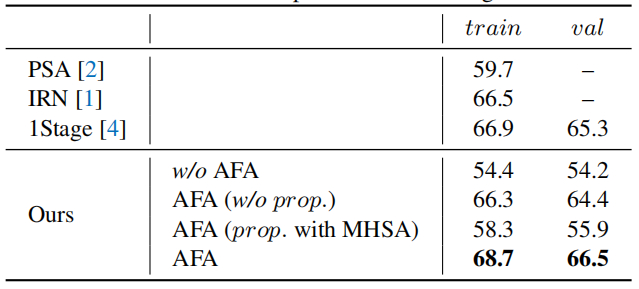
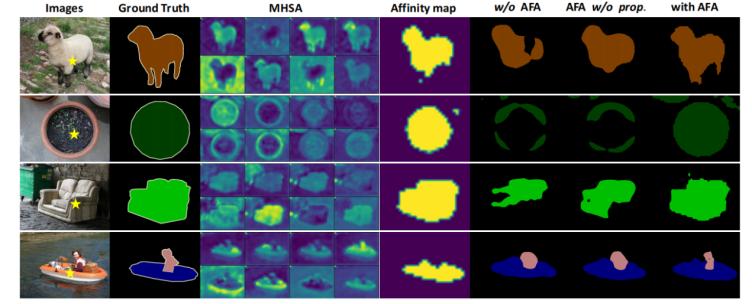
图3. 学习到的mhsa,affinity,及生成的伪标签可视化图
图3和表3中展示了afa模块中多头注意力和语义affinity可视化图,其中表的实验模块为没有afa模块(w/o afa)、有afa模块但没有随机游走传播(afa(w/prop.))、直接用mhsa作为affinity信息(afa (prop. with mhsa))以及使用了完整的afa模块。我们注意到afa损失以及随后的随机游走传播过程都能够有效的提高伪标签效果,以及直接使用mhsa作为affinity信息并不能带来效果提升。
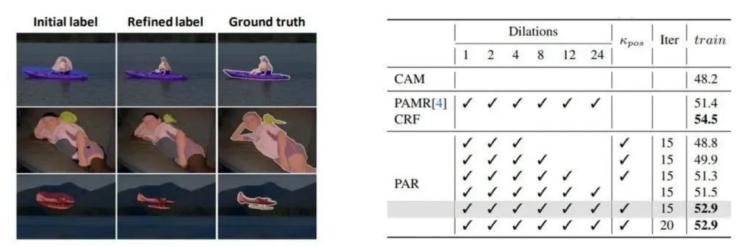
图4. par模块对伪标签的修正效果(左)及不同设置的影响(右)
表4.在voc(左)和coco(右)上的语义分割结果
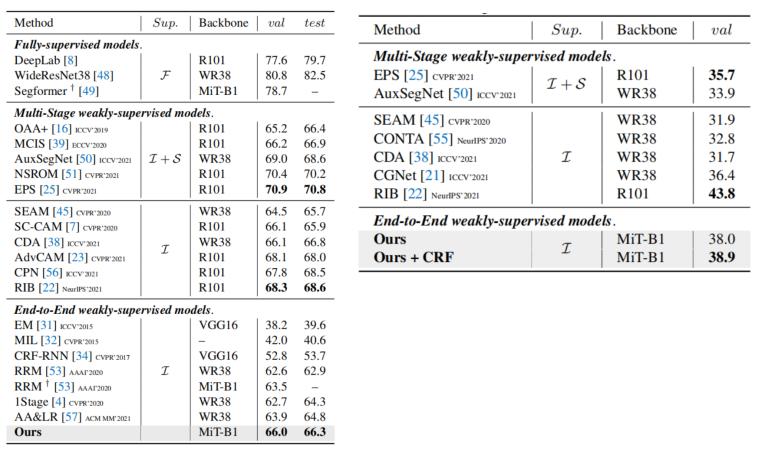
在voc和coco数据集上的实验都显示afa超过了最近的端到端语义分割方法,并且同时超过了部分多阶段的方法以及一些引入的额外显著性监督的方法。
本文探索了transformer架构对wsss任务的内在优点。具体来说就是作者使用一个基于transformer的backbone来生成cam作为初始的伪标签,避免了cnn的固有缺陷。此外,作者注意到了mhsa和语义affinity之间的一致性,从而提出了afa模块。afa从伪标签中获得可靠的affinity标签,强加affinity标签来监督mhsa,并产生可靠的affinity预测。利用学习到的affinity,通过随机游走传播来修正初始伪标签。在pascal voc和ms coco数据集上,本文的方法实现了端到端wsss的sota性能。从长远的角度上来讲,该方法还为视觉transformer提供了一种新的视角,即通过语义关系引导自注意力,以确保更好的特征聚合。
原文链接:
代码链接:
撰稿人:张铠镛
审稿人:何乐为






