 467
467
 0
0
 2023-04-19
2023-04-19
 2023-04-19
2023-04-19
本篇学习报告的内容为:语义、时间和空间一致的视听觉刺激p300脑机接口,并在一个完全闭锁状态的als患者进行探索性测试 ,所参考的文献是《visuo-auditory stimuli with semantic, temporal and spatial congruence for a p300-based bci: an exploratory test with an als patient in a completely locked-in stat》,这篇论文于2022年发表在期刊《journal of neuroscience methods》上。
1. 摘要
虽然在脑机接口领域的研究已经有许多成果,但是成功应用到完全闭锁状态患者的案例还是非常稀少,最多都只是一种基于“是/否”的交流范式。
论文提出了语义、时间、空间一致的p300脑机接口,混合视觉与空间听觉刺激(hva-s)模式,并与单空间听觉刺激模式(au-s)比较。其中空间声音通过头部相关传输函数(hrtf)生成,在10名健康受试者实验中获得了良好结果后,进一步应用到了一个完全闭锁状态的患者身上。
这篇论文与作者之前的研究成果进行了比较:在之前的研究中,作者提出了一种不依赖于凝视的p300 bci,使用三种刺激模式:视觉隐蔽(visual-covert)、听觉和混合视觉听觉模式,其中混合模式是语义、时间一致的。
2. 实验材料和方法
2.1 受试者
依旧是作者之前研究的实验中招募的10名健康受试者,其中6名男性4名女性,他们的听力正常,视力正常
一名完全闭锁状态的患者参加了实验,55岁男性,在实验前已经进入完全闭锁状态95个月。他无法控制运动,除了非常轻微的慢速的垂直眼动,仅用于与家属进行是/否的交流。在实验前22个月他还能通过眼动仪进行交流,但在后面也失去了这个功能。
2.2 实验范式与过程
选择了用于简单交流的一些葡萄牙语词语,设置成刺激。 sim (yes), não (no), fome (hunger), sede (thirst), ar (air, regarding the breathlessness sensation), posição (position, regarding the need of position changing due to pain) , urinar (urinate)。
设置了两种条件的刺激模式。分别是单空间听觉刺激(au-s)和混合视觉与空间听觉刺激模式(hva-s)。hva-s中视觉和听觉刺激具有语义、时间和空间一致性。
视觉刺激通过电脑屏幕传达,听觉刺激通过耳机传达。hva-s中,受试者坐在座位上,面前有一个电脑屏幕,高度可调节使得受试者的眼睛与屏幕中心处于同一水平。听觉刺激由耳机传达。au-s中则没有电脑屏幕。如图1所示。
图1 受试者在实验中的示意图
每次刺激持续时间550ms,连续刺激间隔100ms。
视觉刺激:视觉范式如图2 a所示,7个词语呈现在电脑屏幕的不同位置。刺激发生时该词语会高亮显示。
听觉刺激:听觉刺激包含了7个词语的音频。不同的是,论文使用hrtf将音频通过耳机传达给受试者。使得原本的双耳道耳机能够产生空间中不同方位的声音。
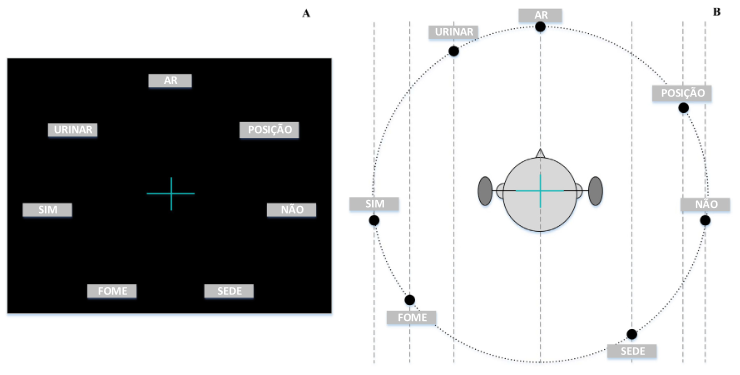 图2 视觉和听觉范式示意图
图2 视觉和听觉范式示意图
不同空间听觉刺激具有不同仰角和方位角,如图3所示。结合图2 a和b能看到听觉刺激和视觉刺激在方位角上的一致(大致)。使用不同仰角是为了让听觉刺激更具有辨识。
视觉刺激与空间听觉刺激一致的原理如下:
①视觉刺激中布局偏上部分的词语与空间听觉刺激中较前方位的相匹配。如词语ar(air),posição(position),urinar(urinate)
②视觉刺激中水平线位置的与空间听觉刺激中两侧的相匹配。如词语sim(yes), não(no)
③视觉刺激中下部分的与空间听觉刺激中较后方位的相匹配。如词语fome(hunger), sede(thirst)
所以实际上视觉布局和声源定位之间没有严格的空间一致性,但是向受试者进行了详细的解释
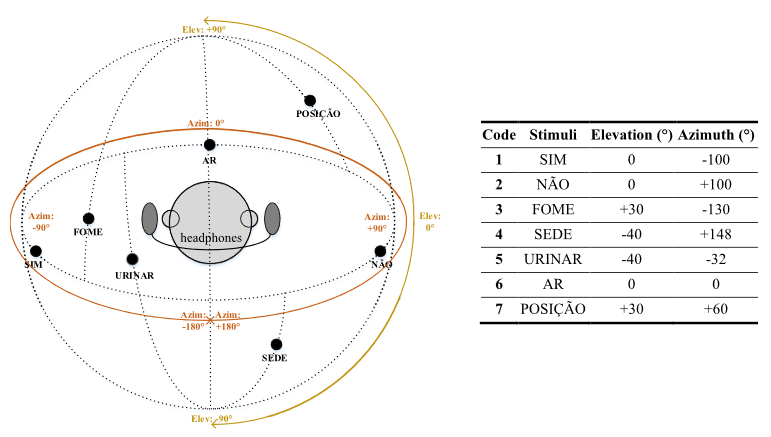
图3 听觉范式种不同刺激的水平角、仰角说明
实验过程:
健康受试者参与了实验一,用于验证提出的bci的有效性。患者参与了实验二,目的是评估bci在完全闭锁状态患者中的可用性。
受试者被告知要计数目标刺激并忽略其他刺激。
每次序列/重复(sequncen/repetition)中包含1个目标刺激和6个非目标刺激,即七个不同刺激都出现过一次,顺序随机。
实验一:每名受试者都经历两个session(首先是hva-s,再是au-s)。每个session首先是校准阶段,用于获取数据训练分类器,之后进入到在线阶段。
①校准阶段:包含了14个trials,每个trial包含10个序列/重复(sequences/repetitions),每个trial之前都提示要受试者集中的目标刺激。共采集了140个目标epochs和840个标准epochs,共用时13mins。
在hva-s中包含了一个眼动检测(ocular movement detector,omd)环节,来去除由眼动对eeg信号的干扰,需要额外用时185s
②在线阶段:包含了15个trials(选择15个词语),每个trial包含了6个序列/重复。在线阶段受试者进行选择的词语是预先定义好的序列(这与校准阶段不同),且两个session中的在线阶段都使用一样的词语选择序列。hva-s中,词语序列通过在屏幕上方显示;au-s中操作员口头表述单词序列。目的是为了获得不会影响结果的中性线索,类似于自由任务。hva-s中,每个trial后通过屏幕反馈给受试者他选择的词语。而在au-s中,完成15个trials后才向受试者反馈,这个操作是为了不混淆听觉提示、听觉反馈和听觉刺激。
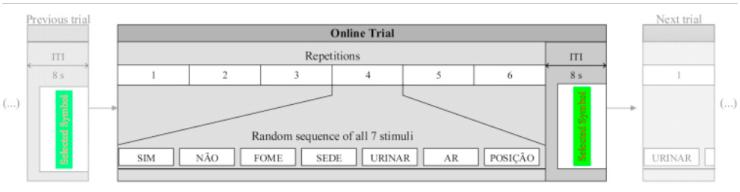
图4 在线trial流程
在线阶段每个trial用时:
6×7×650=27300ms=27.3s,还有8s的序间间隔
实验二:与实验一类似。在患者家中进行,因为病人躺在床上,电脑屏幕位置也进行了调整。在患者家人的帮助下对实验进行了解释,患者用眼球运动回答是/否,不过因为患者眼球运动微小、注意力持续时间短等,回答的效果不佳。患者也未参加问卷调查。
2.3 数据处理
数据采集:使用16个通道的gusbamp采集设备(g.tec medical engineering gmbh, austria)获取eeg和eog信号,采样率256hz。eeg信号采集了16个头皮电位(fz, cz, c3, c4, cpz, pz, p3, p4, po7, po8, poz, oz, t7, cp5, t8 和cp6),左右耳垂作为参考电位,afz作为接地电位。采集eog信号用于检测眼动
数据预处理:信号通过0.5-30hz的带通滤波、50hz的陷波滤波以消除电线干扰。在高速stimulinktm框架中实时采集、处理和分类数据。
2.4 特征提取和分类
提取了每个刺激发生后1000ms的时间窗口。共采集了140个目标epochs和840个标准epochs。如果在检测到水平或垂直眼动,omd做出标记,在之后会被过滤掉。每个trial中,获得了16个eeg记录通道的6次重复的平均值。使用统计学空间滤波器c-fms,将次优(sub-optimally)的两个判别标准结合,应用于16个通道。空间滤波器中两个最具判别性的投影连接成一个向量,通过r2公式选择200个特征,并使用贝叶斯方法训练分类器。
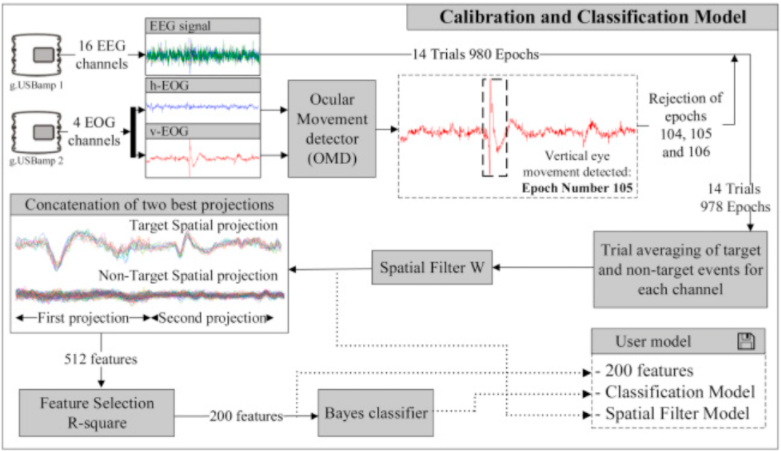
图5 校验和分类模型流程
3. 结果
3.1 实验一
在线阶段:下表是各个受试者在两种刺激模式中获得的准确率和信息传输速率。并与作者之前的研究做了对比(之前的研究刺激模式大致相同,但是没有应用到空间因素,只有语义和时间一致)。即hva-s vs hva ,au-s vs au
与之前的研究相比,应用了空间因素后,hva-s和au-s都获得了更高的平均分类准确率。
hva-s相比于之前的hva,平均准确率从85.3%提升至90.5%
au-s相比于之前的au,平均准确率从52.7%提升至71.3%(p=0.016,具有显著性差异)
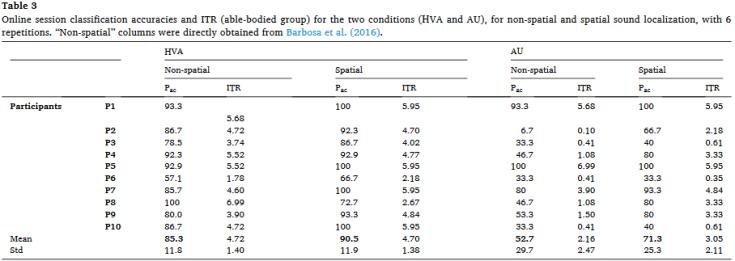
观察标准偏差这一指数,发现不同受试者在听觉模式中获得的准确率偏差大。而au-s比au的偏差又小一些,能够表明hrtf生成空间听觉的方法更具有辨别作用。比较之下,混合刺激模式中偏差比听觉的小,表明多模态刺激模式的有效累积效应。
p300 erp的振幅,潜伏期和宽度:
如图6所示,分析了各个受试者在两种刺激模式下目标刺激发生时的“pz”电位的p300 erp波形。其中粗线为平均波形。
①p300峰值的平均振幅在au-s和hva-s中分别为3.5μv和6.3μv,表明hva-s条件下具有更强的p300。并且在hva-s中甚至发现了双峰,这是视觉和听觉刺激的一致所产生的效应。
②在au-s和hva-s中p300峰值平均潜伏期分别是426ms和411ms,无明显差异。但是若只考虑hva-s中的第一个峰值,hva-s的平均潜伏期则为333ms,与au-s相比具有显著性差异。这个结果可能是因为口语的辨别相比于图像更为困难,au-s中受试者对刺激感知和处理的时间增加。
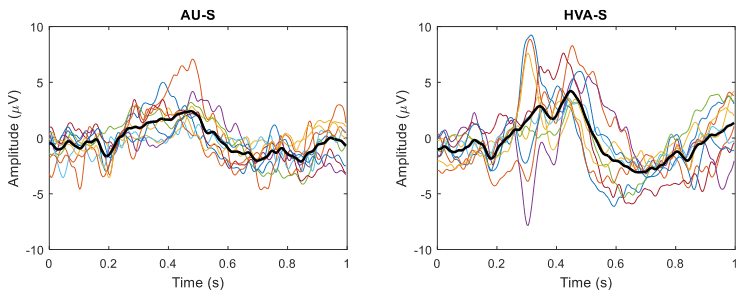
图6 au-s和hva-s实验中pz通道的波形
比较两种刺激模式中目标刺激和非目标刺激在“pz”电位所产生的平均波形。并使用逐点t检验计算16个通道中目标刺激和非目标刺激具有差异的时间点,如图7所示。
在au-s中,具有辨别性的特征位于325-600ms时间窗中,没有覆盖视皮层区域的通道(po7,po8,poz,oz)。
hva-s中,在三个时间窗口出现辨别性特征,分别是270-315ms,440-550ms和600-700ms。前两个窗口显示了视觉刺激和视觉听觉刺激累积的效应。而600-700ms的时间窗口似乎反映了与语义处理的n400成分。总体来说hva-s刺激模式下表现出更强的判别性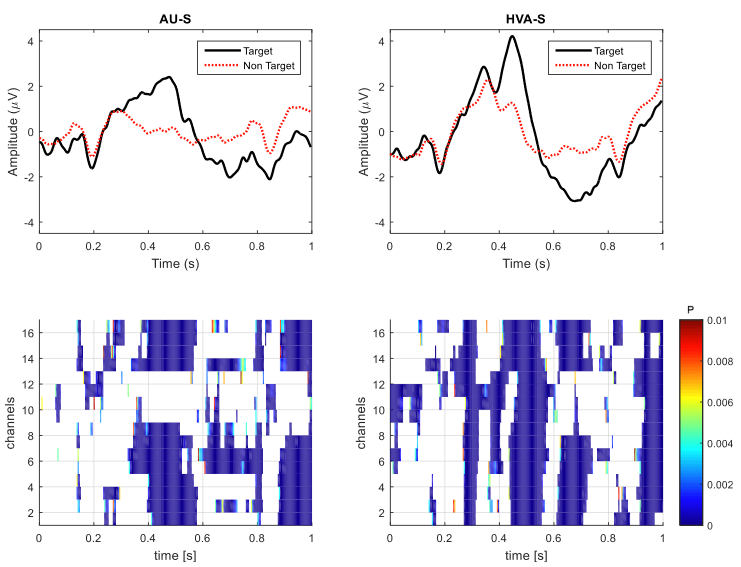
图7
3.2 实验二
分析了一名clis患者在两种刺激模式中目标刺激和非目标刺激在“pz”电位产生的波形,并使用逐点t检验计算16个通道中目标刺激和非目标刺激具有差异的时间点,如图8所示。
au-s和hva-s都没有明显的p300 erp
在一些时间窗口中目标刺激和非目标刺激具有辨别性差异:
在au-s中,两个细小的具有辨别性特征的时间窗,分别在50ms和200ms。200ms的时间窗主要覆盖了中间皮层和听觉皮层通道,但是这个结果在健康受试者组没有发现。
hva-s中,在500ms附近的时间窗口具有辨别性特征,在所有通道中均有覆盖,这个结果与健康受试者组中相似,但是对应的波形却是一个负峰值
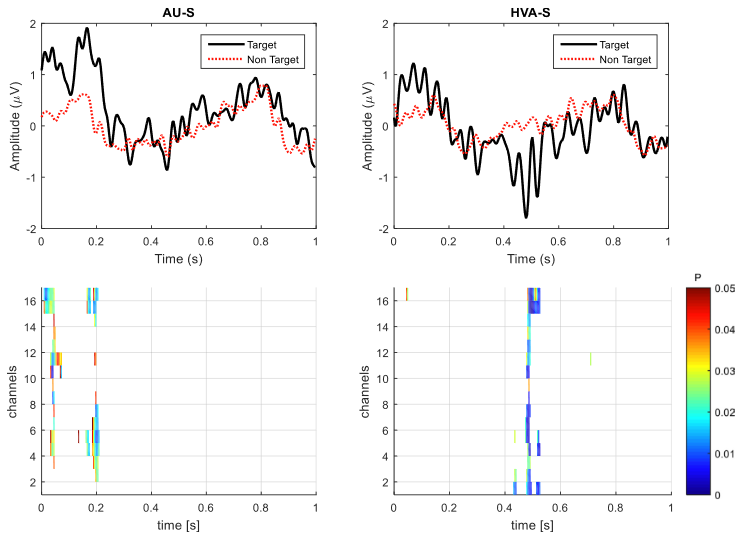
图8
分类准确率:
clis患者在校准阶段的分类准确率如图9所示。使用10折交叉验证方法,分类准确率随每个trial中重复(repetition)数变化而变化。在au-s情况下,重复数为8时错误率为0.1。在患者身上,au-s的结果好于hva-s的
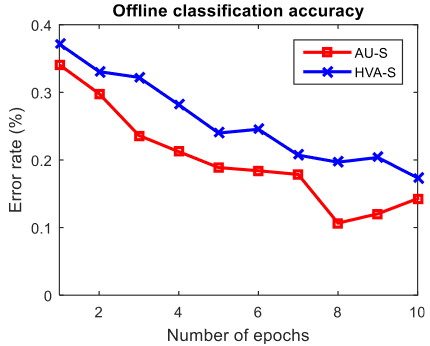
图9 clis患者的离线准确率
采用8次重复的数据启动模型,应用到clis患者的在线阶段中。首先进行au-s session,之后是hva-s session。au-s获得了30%的分类准确率,hva-s获得了与随机水平等同的分类准确率(1/7=0.1429)
4. 总结
健康受试者组分别在au-s和hva-s的在线实验中获得了71.3%和90.5%的平均分类准确率,而患者分别获得了30%和随机水平的平均分类准确率。此外,患者由目标刺激和非目标刺激诱发的的erps,在一些时间窗口中具有显著差异
语义、时间和空间一致的刺激能够在健康受试者组中获得更好的结果,但应用到完全闭锁状态的患者上却不是如此,可能是因为他们注意力和认知功能的损伤,并且因为无法进行进一步交流,难以得知论文使用的hrtf空间方法患者是否完全理解,患者无法对实验范式给出更详细的反馈。患者的独特的erps也比较难解释,需要进一步实验/范式的研究,或者对提出方法进行简化
撰稿人:易智伟
指导老师:王斐






