 1116
1116
 0
0
 2023-03-13
2023-03-13
 2023-03-13
2023-03-13
该篇论文来自于“journal of neural engineering”期刊,发表于2020年12月,论文名称《eeg data augmentation: towards class imbalance problem in sleep staging tasks》。
该篇论文主要想解决的问题包括自动睡眠分段模型存在固有的类不平衡问题(cip),阻碍了分类器获得更好的性能。他们系统地研究了睡眠脑电图数据增强方法。此外,从相关研究领域修改和转移了新的数据增强方法,产生了新的有效方法来增强睡眠数据集。本研究涵盖了重复少数类、形态变化、信号分割和重组、数据集到数据集的传输以及生成对抗网络(gan)5种数据增强方法。我们通过两个数据集,即蒙特利尔睡眠研究档案(mass)和sleep-edf的睡眠分期模型评估了上述方法。
睡眠分期在睡眠障碍的诊断中起着重要的作用。根据美国睡眠医学学会(aasm)[1],睡眠可分为觉醒(w)、快速眼动(rem)、非快速眼动(nrem)三个阶段,其中nrem可进一步分为n1、n2、n3三个子阶段。这些阶段通常使用通过多导睡眠图(psg)收集的睡眠记录来进行,psg包括一组生物信号,如脑电图(eeg)、肌电图和4位作者的任何通信地址。心电图,等。在临床环境中,睡眠记录的解释主要由技术人员手工完成,这是一项费时、繁琐的工作。
近年来,机器学习的进步有利于自动睡眠分期问题[2-5]。虽然这些方法取得了良好的性能,但它们遭受了类失衡问题(cip)。对于一个睡眠记录,每个睡眠阶段的持续时间是不相等的。具体来说,n2阶段占了大多数类别,约占总睡眠时间的45%-55%。而n1阶段仅占2%-5%的[6]。这个问题存在于所有可用的睡眠数据集中,如蒙特利尔睡眠研究档案(mass)数据库[7]和sleep-edf数据库。类上的不平衡可能会阻碍分类器的性能,并限制了睡眠分期算法的进一步改进。
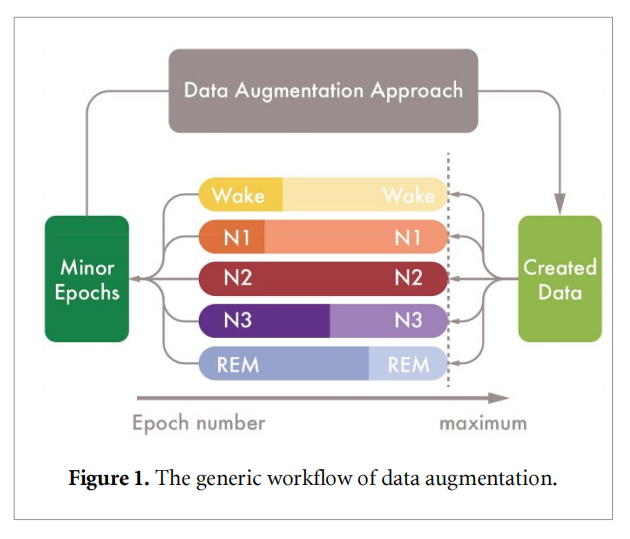
该文章提出了五种数据增强的方法,包括重复少数类(dar)、脑电图信号形态变化(damc)、信号分割和重组(dasr)、数据集到数据集的传输(dat),以及最先进的生成算法gan(dagan)。
少数类的重复样本是一种简单的方法,通过简单地从少数类[2]中随机复制选定的样本。在训练过程中对该方法进行了验证。在我们的研究中,该过程如算法1所示。我们构建了具有所有样本具有平等机会来补偿少数类的增强数据集。

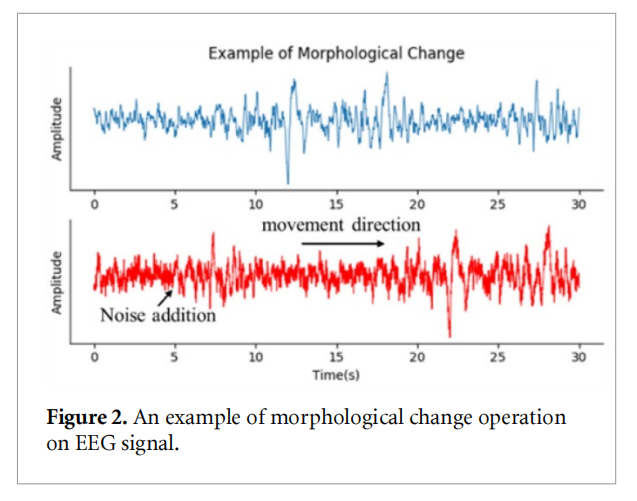
其中,诸如翻转、缩放、旋转等转换是最常用的,并被证明是有效的[19,20]。理论上,从原始睡眠脑电图信号中提取特征与cv中对应的特征相似,因为学习者试图捕捉形状、结构等形态特征,以匹配给定的模板。与[3]类似,我们在cv中为睡眠分期任务定制了da方法。由于脑电图信号是时间序列序列,我们将形态变化的操作简化为水平运动。
对于一个给定的睡眠脑电图历元,我们沿着时间轴进行了一个水平运动。我们还在生成信号中添加了白噪声,以进一步引入可变性。下图显示了这个操作的一个示例。通过对数据集产生新的方差,这些操作不会破坏原始脑电图信号的波特征。
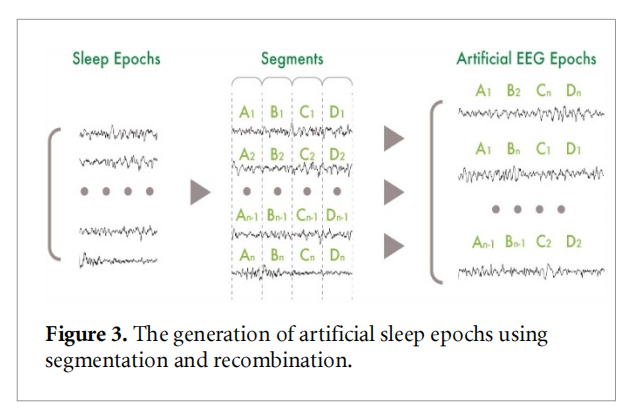
在bci研究中,已经提出了几种有效的方法来解决这个问题,通过生成人工脑电图信号来增强其数据集我们通过在睡眠训练集上使用信号分割和重组策略来探讨这些关于睡眠分期任务的想法。dasr的基本思想是将30s的睡眠时代分为几个部分。然后,通过从同一类别中随机选择和重组的片段来产生新的睡眠时期。如下图所示:
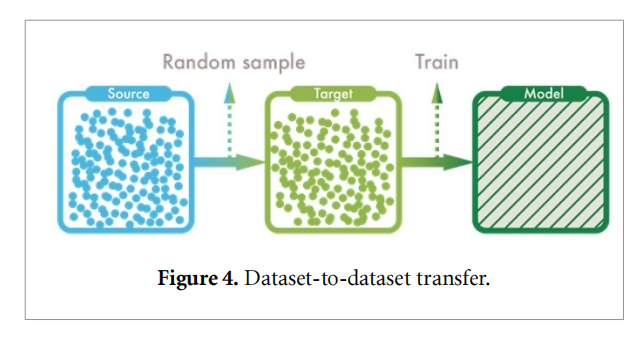
另一种增强训练集的方法是数据集到数据集的传输。睡眠专家可以在不同的睡眠数据集上实现睡眠阶段的分类任务,排除不同的外部因素,如设备、电极和数据收集的环境。这启发了我们使用迁移学习方法[21],该方法通常使用来自源域的辅助数据来支持类似域上的训练。以往的许多研究,特别是在视觉识别领域,已经利用了这些迁移学习方法的优势来实现更好的性能。
假设存在两个睡眠数据集s和t,我们将s定义为源域,t定义为目标域。由于我们的训练目标是从t中准确识别睡眠时期,我们通过采样时期作为辅助数据来处理t上的类不平衡问题。方法如下图所示:
最后一种方法是利用gan模型生成人工脑电图信号。gans在cv、自然语言处理和语音等领域取得了非常重要的成果,证明了其在数据生成方面的优越性能。然而,很少有研究将这种技术应用于合成脑电图。
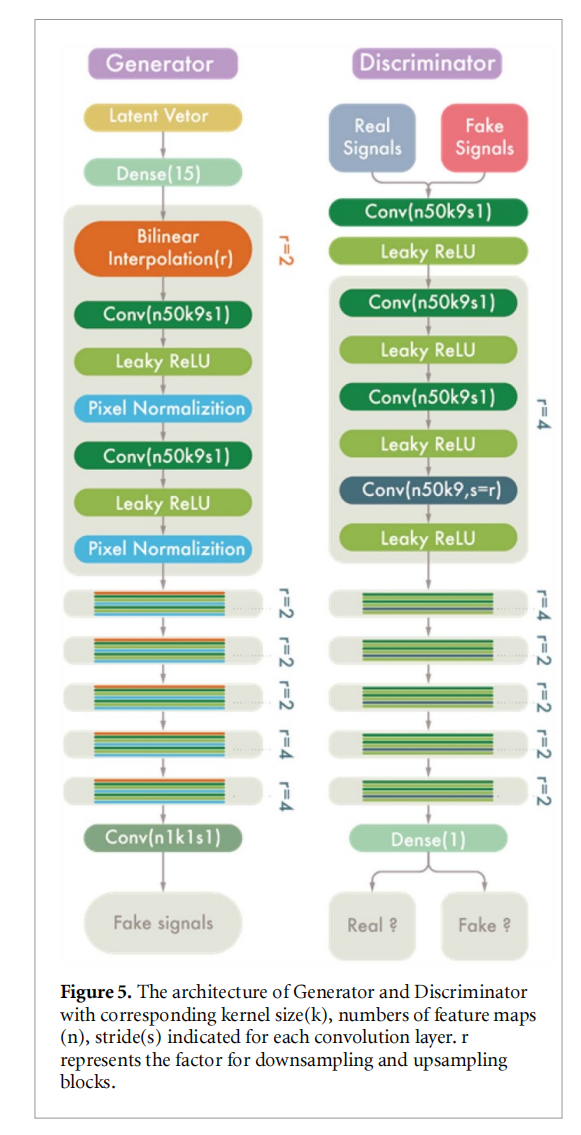
我们的gan模型的架构如下图所示。该模型由两个对称网络、发生器和鉴别器组成。上采样块包含两个卷积神经网络(cnn)层和一个双线性插值块,将输入向量扩大到目标大小。除最后两个块外,每个块上的插值因子为2,其中我们使用因子4来降低输出维数和计算复杂度。相比之下,降采样过程是由cnn层实现的,步幅为2或4。每个cnn层后面都是leakyrelu作为激活函数。特别地,我们在g中的cnn特征图上使用局部响应归一化来保持两个网络的大小匹配。
实验还采用了一些改进的技术,如均衡学习率和小批量标准差。采用了一种渐进式的层渐减训练策略作为,以提高训练的稳定性,减少计算时间。使用adam优化器来更新网络权值。
实验采用了5倍交叉验证策略来评估分类性能。首先以4比1的比例将所有受试者随机分为训练集和测试集。在实验过程中,严格地将训练集与测试集分开。只有来自训练集的数据被用来使用da方法生成新的数据。增强训练集用于模型训练。这个测试集完全独立于训练程序。因此,没有使用任何关于测试集的信息。以下是两个睡眠数据使用五种数据增强方法后的性能改进:
1.dar是最直接的方法,对acc、f1评分和κ的睡眠-edf评分分别提高了1.7%、1.4%、2.61%和2.72%、2.51%、4.04%。通过f1分数测量的显著性能改善是在睡眠edf上实现的(每个验证折叠平均表现的配对t检验p<0.01)。使用da方法对mass的f1得分也有提高,但没有显著性(p > 0.05)。与平均水平相比,dar获得的指标在所使用的两个数据集上表现稳定。
2.在acc、f1评分和κ方面,使用dagan的性能改善分别为3.79%、3.48%、5.43%,在κ方面分别为4.51%、3.14%、5.8%。f1评分在mass(p < 0.05)和睡眠edf(p<0.05)上与基线均有显著差异。值得注意的是,dagan优于其他方法,特别是在大质量数据集上。所得到的f1分数是所有方法中最高的。在两个数据集上,所有指标所衡量的分类性能都在不断提高。这表明,达干地区受现有数据库原始分布的影响较小
3.dasr有助于促进性能改善的显著趋势(p = 0.055)由f1分数测量的睡眠-edf数据集。同时使用dasr技术,睡眠-edf上的acc和κ值最高。然而,在mass上的性能改进相对不那么显著,所有指标都低于所有方法的平均值。这表明dasr的有效性在所采用的训练集上并不是稳健的。
4.同样地,dat在两个数据集上的性能提高也有显著差异。f1评分改进在两个数据集上都具有统计学意义(提高了4.2%和2%,p<分别为0.01和p<为0.05)。然而,与所有方法的平均值相比,mass上的acc和κ相对较低。
5.在大多数情况下,damc获得的结果最不令人满意。然而,在两个数据库上的性能通常是健壮的。在睡眠-edf数据集上,f1评分与基线值(p < 0.05)相比有显著性差异。
论文链接:
撰稿人:吴潮煌
审稿人:李景聪






