 804
804
 0
0
 2023-02-26
2023-02-26
 2023-02-26
2023-02-26
本次分享的学习报告将围绕在2022年cvpr上发表的一篇名为《a convnet for the 2020s》的论文进行讲解,论文第一作者为zhuang liu,由facebook ai研究团队和加利福尼亚大学伯克利分校(uc berkeley)共同完成。该论文针对当下vision transformer火爆cv领域后传统cnn架构该如何优化改进的问题,提出了一些思路并通过实验验证了思路的可行性。
随着google团队在2020年将transformer应用在图像分类任务中,提出具有里程碑意义的vision transform(vit)模型,一系列在vit基础上魔改的transformer网络被用于图像和视频分类任务中,并均取得了较好的成绩,一时间传统cnn架构的网络似乎陷入了窘境。针对这一情况,作者深入思考了transformer到底是厉害在哪并且对cnn架构的网络进行了一系列改进,提出了convnext网络,并在多个任务上取得了优于transformer的结果。
二、提出的方法
该论文借鉴swin transformer架构中的特点,把对cnn(这里作者选用resnet50)的改进归纳为5个部分,分别是macro design、resnext-ify、inverted bottleneck、large kernel sizes和 micro design。
macro design:resnet中的卷积阶段分布的设计主要是经验性的,比例为3:4:6:3,而在swin-t中比例为1:1:3:1,并且swin transformer系列模型在第三阶段均堆叠block的占比更高,这可能是为了兼容下游任务,因此作者将resnet中的卷积阶段堆叠次数修改为3:3:9:3(即1:1:3:1)。同时借鉴swin transformer的下采样策略,将大小为4x4,步长为4的卷积层取代之前resnet风格的stem cell下采样策略。
resnext-ify:resnext网络通过使用分组卷积使得网络在准确性与计算复杂度(flops)得到较好的平衡。作者在这里借鉴resnext的方法引入了深度卷积(分组卷积的一种),并将卷积核的通道数增加到与swin transformer相同的通道数。
inverted bottleneck:如图1所示,resnext中的bottleneck结构为两头粗中间细(即中间通道数小,而上下通道数大),而transformer block中的mlp模块和mobilenetv2的inverted bottleneck模块类似,都为两头细中间粗的结构,故同样在提出的方法中使用后者这样的结构形式。
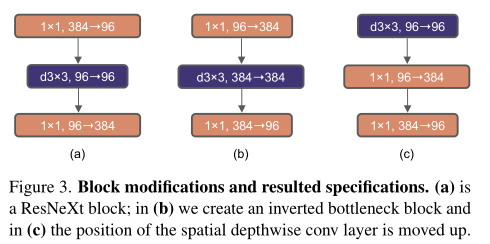
图1 网络块的结构设计
large kernel sizes:transformer的一个突出优势便是利用自注意力机制实现长距离的依赖,并且在swin transformer中使用7x7的滑动窗口,故作者考虑将网络的卷积核大小进行扩大,同样变为7x7。同时类似于transformer中多头自注意力机制被放置在mlp模块之前,作者将网络中的深度卷积操作向上迁移,以此减小总体计算量。
micro design:考虑到transformer和resnet之间的一个区别是transformer里的激活函数和归一化层更少,所以作者同样将原本网络中的激活函数和归一化层大量删除,只保留两个1x1卷积层之间的一个激活函数。同时参考transformer的结构,分别用gelu和layernorm替换原来的relu激活函数以及原来的batchnorm。为了更贴合transformer的结构,作者还参照swin transformer的采样方式,使用了步长为2的2*2卷积代替了原本3*3部分的下采样操作。
三、实验
实验用到的数据集有imagenet-1k、coco和ade20k,其中后两者主要用于分割检测任务,这里不进行过多介绍,重点在于前面分类任务数据集的实验。
根据图2在imagenet-1k数据集上的消融实验可知,macro design部分的卷积阶段分布以及下采样的改进都使得提出的网络模型在性能上有所提升。resnext-ify的深度卷积可以大减少模型的计算量,并通过将卷积的通道加宽将准确率提高到了80.5%。inverted bottleneck中两头细中间粗的结构替换掉原来的两头粗中间细结构后,网络模型的准确率由80.5%提高到80.6%,同时这样设计后残差连接层的计算量会显著降低,使得网络模型整体的计算量也由之前的5.3gflops降至4.6gflops。在large kernel sizes部分,通过对不同卷积核大小的尝试,发现当取得7x7时模型准确率达到最佳,而7x7的大小也与swin transformer中的滑动窗口大小一致。最后在micro design部分,更少的激活函数和更少的归一化层分别可以使得网络模型的准确率提升0.7%和0.1%。此外将layernorm替换掉batchnorm后网络模型的准确率也由原来的81.4%提升至81.5%,这可能是batchnorm比layernorm更为复杂,可能会对模型的性能产生不利影响。最后通过为convnext网络单独设计了一个下采样层,即laryer norm后加上一个卷积核大小为2,步长为2的卷积层后准确率由原来的81.5%提升到了82.0%。
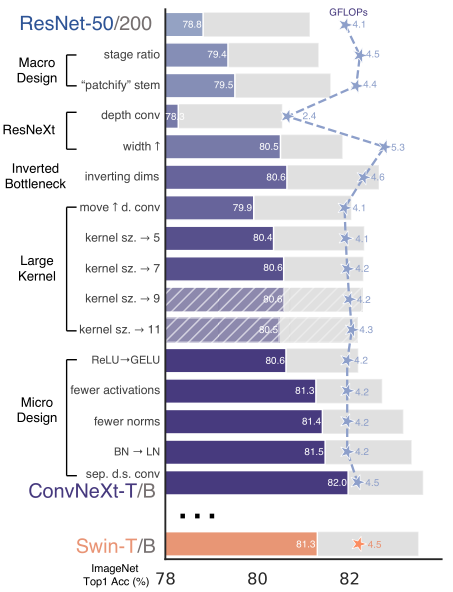
图2 在imagenet-1k上的消融实验
同时为了说明本文提出的convnext网络结构具有较好的性能,根据swin transformer的 swin-t, swin-s, swin-b,swin-l分别构建出convnext-t、convnext-s、convnext-b以及convnext-l(t、s、b和l的区别在于特征维度不同和每个卷积阶段的层数不同),并将这些方法以及当下一些经典的网络模型在imagenet-1k数据集上进行了分类任务的实验。根据图3所示,本文提出convnext架构的网络模型准确率均好于对应的swin架构的网络模型,说明了在将transformer的特点迁移到cnn网络后,传统的cnn架构网络依然具有较高的竞争力。
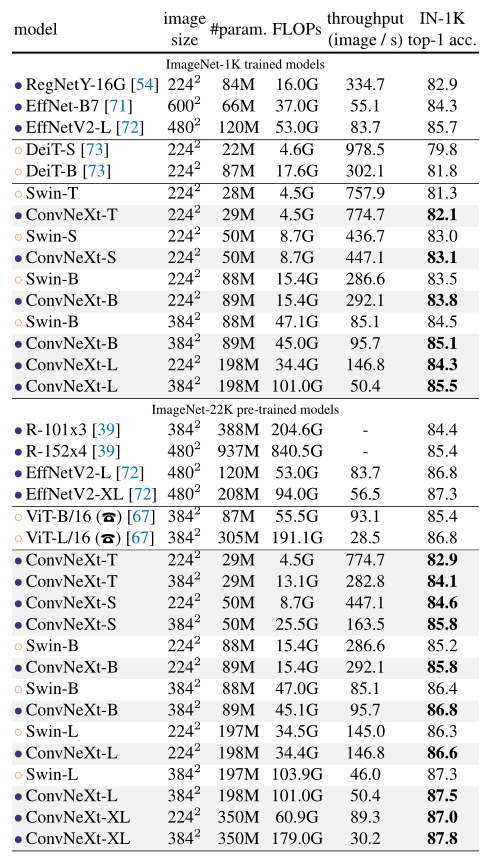
图3 各种方法在在imagenet-1k上分类准确率
四、学习总结
该论文通过分析transformer(这里为swin transformer)与resnet网络的差异,从5个部分将resnet进行不断的改进。这些改进初看可能觉得并没有太多创新,因为使用的全部都是现有的结构和方法,但仔细思考后又会有所收获,因为这些改进方法或者结构往往是经过许多研究者进行大量实验得出的,具有一定的普遍通用性。在这之前并没有人很好地将这些对网络模型的改进型方法进行归纳总结,而在论文中作者就对其进行整理并运用在resnet网络上,提出了convnext网络。后经实验得知,这些改进方法在没有增加太多计算量的同时将convnext的准确率由78.8%提升至82.0%,足以媲美火遍当下的transformer架构的网络模型,也说明了cnn架构的网络模型在cv领域依旧具有一定的竞争力。
参考文献
撰写:周卓沂
审稿:梁艳






