 587
587
 0
0
 2023-02-26
2023-02-26
 2023-02-26
2023-02-26
本篇学习报告来源:《cross-subject eeg emotion recognition combined with connectivity features and meta-transfer learning》,论文发表在《computers in biology and medicine》期刊上(sci q1,中科院二区,if: 6.7438)。作者是来自华南理工大学电子信息工程学院的jinyu li等人。作者提出了一种结合连接特征的残差网络和新的元迁移学习(学习新的被试)的跨被试脑电情绪识别方法。
因脑电信号个体差异巨大而跨被试情绪识别一直是一项巨大的挑战。激活特征已经成为脑电情绪识别的典型特征,而cnn的不同感受野可以捕获不同大脑区域的相互作用,因此连接特征可能存在很多可识别的潜在信息。传统的元学习方法是在学习一个在新的类上表现良好的模型,应用元学习方法去学习一个新的被试而不是一个新的类别是一个新的思路。
(1)提出了一个结合了 msrn、mtl 和连接特征优点的模型。该模型采用mtl策略减少个体差异的影响,多尺度捕捉不同情绪状态下不同脑区之间的相互作用,对于提高泛化能力和解释情绪的生理意义具有重要意义识别模型。
(2)在 deap 和 seed 数据集上进行了实验,在valence和arousal任务上都比传统方法获得了更高的准确性。
(3)验证了相位特征在脑电情绪识别中更有效,这指导我们后续工作探索情绪变化时不同脑区的协同作用。
本文提出的是结合msrn和mtl策略的mtl-msrn方法。msrn由多尺度残差块构建,以提取 eeg 信号的连接特征,利用 cnn 的不同感受野来捕获不同脑区的合作。 mtl 策略结合了元学习和迁移学习的优点,以缓解跨学科个体差异的问题。
将连通性特征与 msrn 相结合,提出了一个 msrn 模型来区分情绪类别,如图 1 所示。在 msrn 中,首先从预处理的 32 通道 eeg 信号中提取连通性特征。连通性特征的尺寸为 4×32×32。数字 4 代表四个频带(θ(4-7 hz)、α(8-13 hz)、β(14-30 hz)和 γ(31- 50 hz))用于eeg信号的分解,而32代表eeg通道数。因此,32×32 表示 eeg 通道之间的连接特征。每个值代表特定频段内两个 eeg 通道之间的连接特征。在 msrn 模型中,第一层是具有 64 个过滤器且卷积大小为 3×3 的普通卷积层,然后是最大池化层。多尺度(ms)模块主要用于通过融合不同脑区特征来提取多尺度连接特征。设置全局平均池化层以展平特征并减少模型的工作量,然后是两个全连接的层。最后,使用 softmax 层来区分情绪类别。
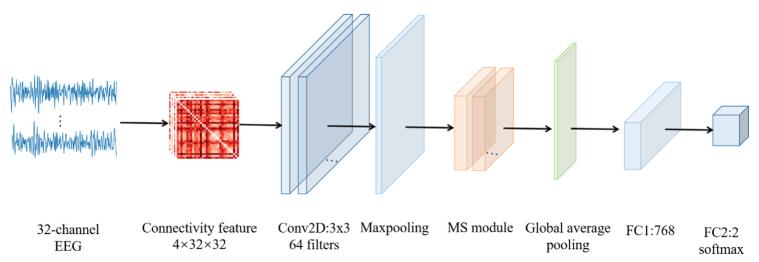
图1,msrn的框架图。第一卷积层和maxpooling层用于下采样和去除冗余信息。ms模块主要用于多尺度连通性特征的提取。全局平均池化层被设置为平滑特征并减少模型的工作量。使用softmax层来区分情绪的类别。
如图2所示,多尺度模块主要由三个分支组成:3×3残差块、5×5残差块和7×7残差块,卷积核大小分别为3×3、5×5和 7 × 7。残差网络的框架可以通过跳跃连接的结构更好地捕获和融合脑电信号的特征。粗体“×3”表示残差块将使用不同的过滤器重复训练三次。
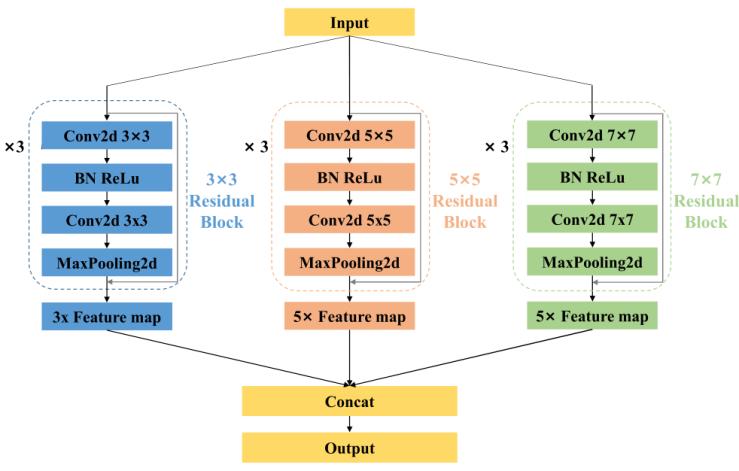
图2,多尺度模块框架。该模块主要包含三个分支:3×3 residual block、5×5 residual block、7×7 residual block;每个残差块用不同的过滤器重复训练3次,通过融合不同的脑区特征来提取多尺度连接特征;最终输出的大小为 768。
功能连接特征反映了不同脑电通道的相关性,维度为32×32,每个节点代表不同脑电通道的活动强度。采用多尺度方法,每个分支的卷积层大小不同,意味着不同通道的连通性特征可以用不同的感受野被充分捕获,这可以充分反映不同大脑区域的相互作用。
预热阶段:传统的元学习算法,如 maml,总是以随机的方式初始化模型的权重,这需要大量相似的任务来表示特征。在预热阶段,使用了预训练的方法。源域中的所有训练样本都用于训练初始模型,从而能够在后续阶段快速收敛。定义一个特征提取器 θ(msrn 中的卷积层)和一个分类器 θ(msrn 中的最后一个全连接层)。然后,使用等式 (1)、(2) 中的梯度下降优化特征提取器 θ。其中ld为交叉熵损失函数,α为学习率。
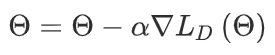 (1)
(1)
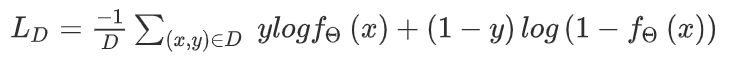 (2)
(2)
在预热阶段,通过梯度下降学习特征提取器 θ。因此,该模型可以从源域中的所有被试学习脑电信号的共同情绪模式。通过迁移学习,模型可以学习到脑电特征的浅层语义特征,这对模型的鲁棒性有显着贡献,使模型能够在元训练阶段快速收敛。
元训练阶段:提出的方法可以通过梯度下降的小步骤来优化模型的参数,从而在未知的被试中取得了良好的性能。更具体地说,优化的目标如下:
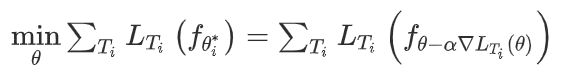 (3)
(3)
在元训练阶段,将从源域(涉及的被试)采样的任务分为支持集和查询集两部分,分别训练两个模块,分别命名为base-learner和meta-learner。支持集中的主题与查询集中的被试不同。训练base-learner以学习不同被试之间的共同脑电图特征。此外,在base-learner的训练过程中,特征提取器 θ 会再次更新。meta-learner可以学习跨被试的个体脑电图特征。在meta-learner的训练过程中,特征提取器θ被冻结以确保学习到的共同脑电特征保持不变,而分类器θ可以从查询集中学习以微调个体脑电特征。
在元训练阶段使用了二次梯度更新方法。支持集首先用于完成第一次梯度更新。此后,使用查询集和从第一次梯度更新中获得的参数计算第二次梯度更新。使用 adam 优化器,将第二次梯度更新期间计算的梯度直接应用于 msrn 模型。使用查询集进行第二次梯度更新,以增强模型对未见主题的适应性。借助元学习,模型可以避免对某一受试者的脑电数据过度拟合,更多地了解脑电特征的通用性。
元测试阶段:元测试阶段的进展与元训练阶段相似。来自目标域的数据也分为支持集和查询集,但数据未标记。元测试阶段有两个差异。在元训练阶段训练的参数[θ*; θ*]最初用于元测试阶段,而不是以随机初始化的方式使用。其次,支持集用于更新特征提取器θ,但是由于从测试集中采样的查询集数据未标记,分类器θ没有更新。查询集由在元学习阶段微调的分类器分类。最后,评估了测试集的准确性。
使用deap数据集,提取4个频带θ (4–7 hz)、α (8–13 hz)、β (14–30 hz) 和 γ (31–50 hz)的三种特征:pcc、plv和pli。每种类型的连接特征的维度为4×32×32。数字4代表脑电信号分解中使用的四个频段,而32代表脑电通道数。使用loso验证策略。
pcc:是一个线性相关系数,反映了不同通道脑电信号之间的线性相关性,可以描述为
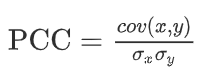 (4)
(4)
其中 x 和 y 表示来自不同通道的两个 eeg 信号,cov(x,y) 是 x 和 y 之间的协方差,σx and σy分别表示 x 和 y 的标准差。 pcc的值位于-1和1之间,绝对值越大,线性相关性越强。
plv:通过计算相位差的平均值来描述两个eeg信号之间的相位同步,可以描述为
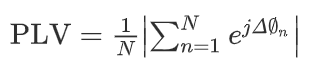 (5)
(5)
其中 n 表示 eeg 信号的采样点,并且δ∅n表示第 n 个采样点的相位差。使用hilbert–huang变换来计算两个 eeg 信号之间的相位差。 plv 的值位于 0 和 1 之间。如果两个信号完全相位同步,则 plv 为 1。
pli:是另一种衡量两个信号之间相位同步的方法,通过计算相位差的平均值和符号函数,可以描述为
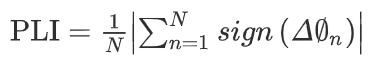 (6)
(6)
其中n为脑电信号的采样点数,sign(.)表示sign的函数,δ∅n表示第 n 个采样点的相位差。
在训练阶段,选择了 adam 优化器作为训练优化器,同时将 dropout 设置为 0.2 来解决过拟合问题。实验的批量大小设置为 64。预热阶段的 epoch 设置为 10,而元训练阶段的 epoch 设置为 50。base-learner的学习率设置为 5 × 10−3,而meta-learner的学习率在元训练和元测试阶段均设置为 5 × 10−4。学习率每 100 步衰减两次,以确保梯度下降的稳定性。使用提前停止方法来避免过度拟合。最大池化层的内核大小设置为 3 × 3,步幅设置为 2,填充设置为 1。对于 3 × residual block,每层的形状为 (4, 32, 32),(64、32、32)、(64、16、16)、(128、8、8)、(256、4、4)和(256、1、1);对于5×residual block,每一层的形状为(4, 32, 32)、(64, 32, 32)、(64, 15, 15)、(128, 6, 6)、(256, 2, 2)和 (256, 1, 1)。对于7×residual block,每一层的形状为(4, 32, 32)、(64, 32, 32)、(64, 14, 14)、(128, 6, 6)、(256, 2, 2)和(256, 1, 1)。最终连接到全连接层的输出为768。由于采用了loso交叉验证,每个实验的训练集包含31名受试者的数据,24800个样本,测试集包含1名受试者的数据,有 800 个样本。
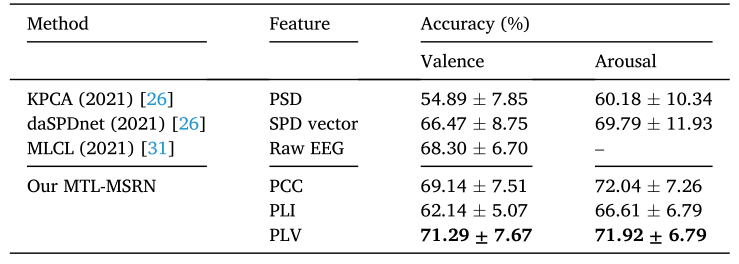
提出的方法在deap数据集的valence方面达到了 71.29% 的准确率,在arousal方面达到了 71.92% 的准确率。与同行相比如下表1。
表1,跨被试eeg情绪识别准确率及相关工作的标准差比较(基于deap数据集)。
在seed数据集上,跨被试准确率87.05%,与其它方法的比较如下图3。
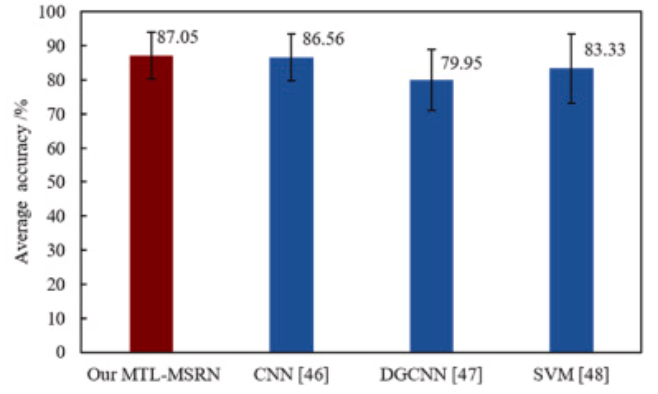
图3,seed数据集上与其它方法的准确率比较图
另外,作者还实验证明了所使用的特征中plv的特征效果最好。
分享人:梁容铭
导师:潘家辉






