 729
729
 0
0
 2023-01-17
2023-01-17
 2023-01-17
2023-01-17
本篇学习报告介绍一篇2022年发表在 ieee transactions on multimedia的论文《spatio-temporal pain estimation network with measuring pseudo heart rate gain》,第一作者是dong huang,由西北工业大学、西北农林科技大学、芬兰奥卢大学、西北大学合作完成。该文章提出了一种通过面部表情分析识别疼痛的新方法,从原始视频中生成新的模态数据,并利用这些数据通过端到端网络联合估计疼痛程度。作者设计了一个疼痛估计时空网络,该网络采用双分支框架分别提取疼痛感知的视觉特征和伪生理特征并融合这两种特征。在两个公开的数据集上进行的实验表明,引入新的模态数据的方法是有效的,所提方法的性能优于现有的方法。
一、研究背景
在过去的十年中,人们不断探索各种疼痛估计的技术。疼痛自动识别系统的结构组成主要包括数据获取、数据预处理、特征提取以及分类等。疼痛自动识别的方法主要包括行为、语音、生理以及多模态融合等4个方面。
在行为疼痛反应中,因为面部表情相比其他行为表明的疼痛信息更为丰富,所以面部表情识别疼痛一直以来更受研究者关注。然而,仅基于静态或动态的面部图像估计疼痛强度的方法主要涉及视觉面孔,不能利用其他线索。疼痛发生的同时会伴随生理指标的变化,基于生理测量的疼痛分析,即使用心率增益(hrg)作为辅助信号,可以从参与者的生理反应中提取疼痛相关特征。
二、方法
文章介绍了以两种分支(即视觉和生理)估计视频中的疼痛强度的方法,流程图如图1所示。该方法主要包括数据预处理、深度网络和参数学习三个过程。在对视频序列进行预处理后,将其输入双分支网络以提取动态疼痛感知特征。视觉分支提供来自面部区域的视觉特征,而生理分支输出心率增益(hrg)作为生理模态的表示。在此基础上,实现了hrg分析仪,将hrg与疼痛强度联系起来,并结合hrg与视觉分支进行最终的疼痛估计。
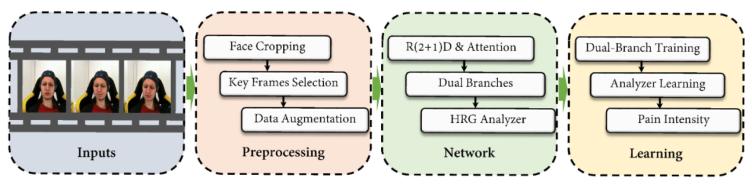
图1 方法的流程图
1、预处理
在将疼痛视频输入深度模型提取双模态特征之前,需要对原始视频数据进行预处理。预处理过程如图2所示,主要包括人脸裁剪、关键帧选择和数据增强。
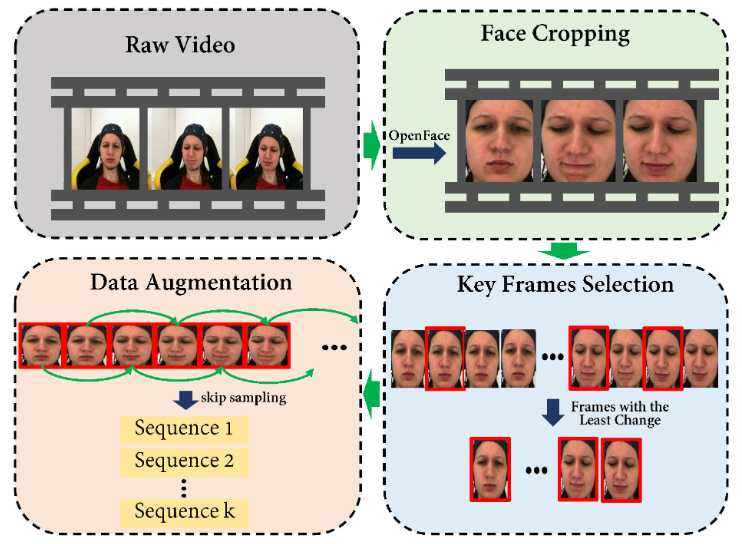
图2 预处理流程图
2、双分支深度网络
双分支深度网络架构包含三个子部分:共享块和特殊结构、视觉和生理分支、模态融合和疼痛估计,如图3所示。首先,采用多个层提取时空动态信息,为后续的双分支特征分析提供丰富的信息。然后,提取面部动作特征以及从该网络生成伪hrg,进一步提取生理特征。因此,这个深度网络由两个分支组成,一个用于视觉疼痛特征,另一个用于伪生理特征。最终,系统充分考虑伪生理模态和视觉模态的影响,得到一个全面的疼痛估计。
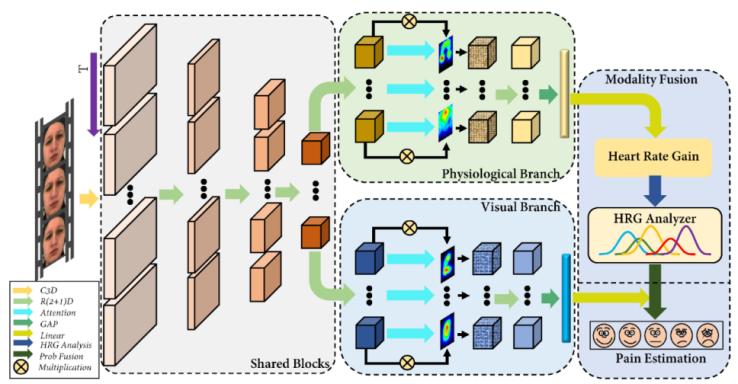
图3 整体网络结构
三、实验
(1)数据集
该论文选择biovid和mint数据集作为基准数据集。在实验中,所有数据都采用预处理程序进行处理。

图5 数据集部分例子
(2)消融实验
文章首先评估三种卷积滤波器的有效性,分别包括:c3d,r3d和r(2 1)d滤波器。为了公平比较,只替换卷积核(即c3d和r3d),而保留所提出的网络的其他部分。结果如表2所示。实验结果表明,采用r(2 1)d卷积算法可以获得最佳的性能。这表明该卷积滤波器在疼痛估计中具有更好的特征表示能力。图6所示的训练过程表明,r(2 1)d收敛更快,表明该网络更容易优化时空解耦的操作。
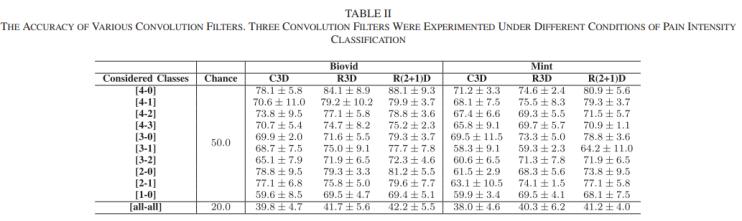
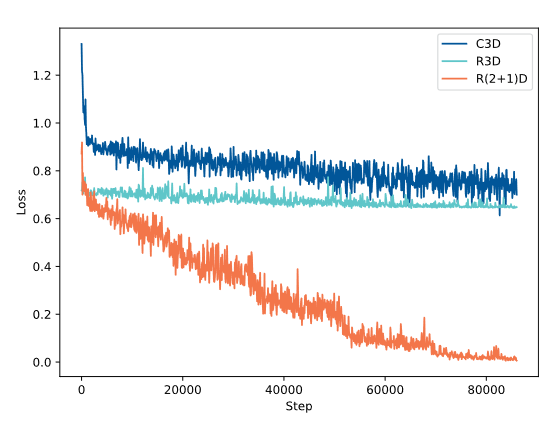
图6 三种卷积分类器的损失函数下降情况
文章提出使用注意结构使深度网络更加关注疼痛估计的重要区域,例如在空间域中面部纹理变化的区域和在时间域中包含疼痛表情的帧,结果如图7所示,其中position =4和position =0分别表示有注意结构和没有注意结构的网络。可以看出,有注意力的网络性能更好。其中一个原因可能是,注意力结构使深层网络能够专注于重要的信息。由于视频中包含大量冗余信息,因此疼痛估计任务只需要关注相关内容即可。
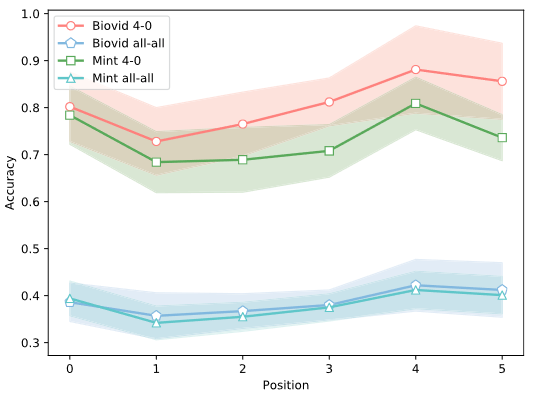
图7 注意力机制施加在网络不同位置对网络的影响
从热图上观察,注意力结构使疼痛感知区域更加显著,例如眼睛、鼻子区域。然后,文章探索了注意力机制的施加位置是否会对结果产生一定的影响。结果如图8所示。从结果可以看出,在高级语义特征部分添加注意力机制会降低准确率。原因可能是这些特征的感受野还不够大,相关的疼痛区域还没有被涉及。

图8 注意力机制在视觉和生理分支的热力图
此外,从视觉分支和生理分支的比较来看,疼痛估计任务中两者可以互相提供更多信息,提高准确率。文章还测试了所有参数完全共享的情况,结果如图9所示。这说明面部疼痛和伪生理特征的重点关注区域并不完全是同一区域。虽然它们在低级特征上可能有一些相关的联系,但在注意力机制层上存在一些差异。为了验证文章的想法,文章还将生理分支的注意图可视化,如图8第3行所示。
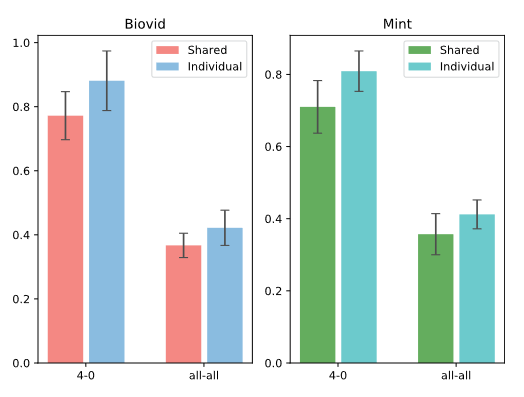
图9 共享网络参数和独立网路参数的结果对比
通过与视觉分支注意图的比较可以看出,虽然这些任务是相关的,但它们对重要信息的表现形式是不同的。因此,文章提出的视觉疼痛估计和生理hrg估计的双分支是必要的,这种方法既能挖掘这些任务之间的内在联系,又能适应单个任务的独特性。
(3)与现有方法的比较
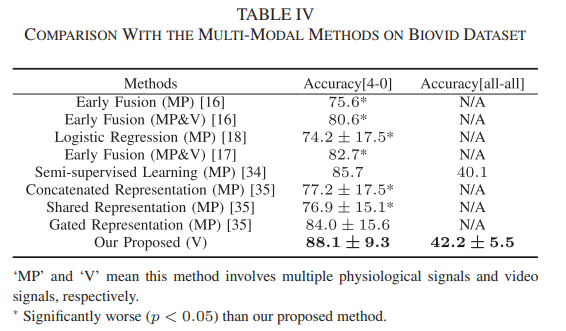
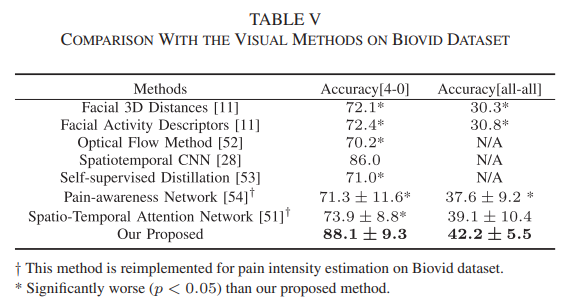
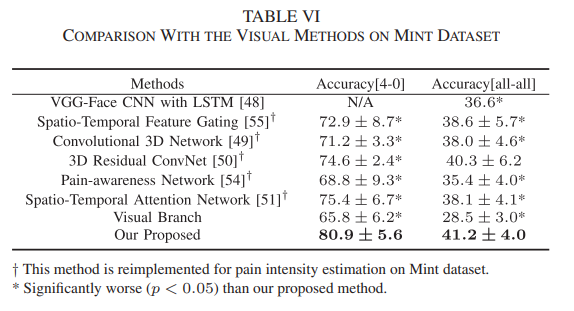
在biovid数据集,作者把提出的方法与一些多模态方法(结合不同的生理信号,或者把生理信号与视频信号相结合)、视觉方法进行比较,结果分别见表4和表5。此外,作者复现了一些在动作识别中具有代表性的视觉方法,把提出的方法和这些方法在mint数据集上进行比较,结果见表6。从实验结果可以看出,提出的方法取得最好的结果。
四、总结&启发
论文链接:https://ieeexplore.ieee.org/document/9479776
撰稿:彭敏轩
审稿:梁艳






