1344
1344
 0
0
 2022-11-13
2022-11-13
 2022-11-13
2022-11-13
2022年11月4日,脑电生物特征识别暨2022脑机接口算法挑战赛颁奖仪式在线上召开。蚂蚁集团蚂蚁安全实验室天玑实验室作为参赛者做了以“基于目标迁移的多模脑纹识别方案”为主题的比赛分享。
天玑实验室分享人首先从测试周期、精确度、国内外行情及行业使用等多个角度,分享了生物安全检测认证体系的先进性,同时也分享了蚂蚁安全实验室在生物安全检测方面的领先。
接下来,分享人从赛题任务及赛方提供的数据出发,总结得出在脑电识别上的任务是要识别出跟行为和任务无关的脑电信号,即人的唯一表征。在验证上的任务是主要是将新测得的信号与原有的信号进行验证是否来自同一人;在识别上的涉及到的检索和相似度度量问题会比验证任务更具有挑战性。
在数据分析方面,分享方基于自己的理解,运用了baseline提供的预处理方式,如采用小波函数进行小波变换;在时域信号的处理上,分享方根据参考的资料,采用了梅尔谱滤波、倒梅尔谱系数等方法,在频谱上做出了分析处理。在算法结构方面,分享方设计了一个统一的特征编码器,可支持预训练、对比学习和度量学习等多种方式的进行。
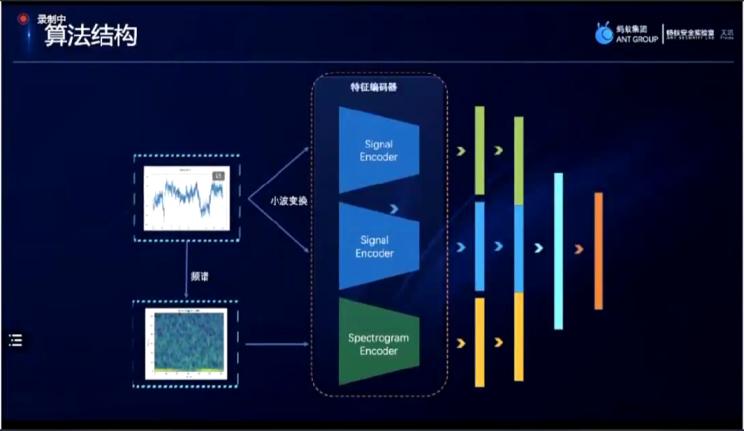
在编码器方面,分享方做出了两个小设计。首先是参考baseline方式,对编码器进行了改变,如图中所示m5编码器,对于信号输入,经过卷积 batch normalization 池化的五层网络进行一个特征的提取;对于二维的频域,将会进入结构一样的二维卷积编码器。
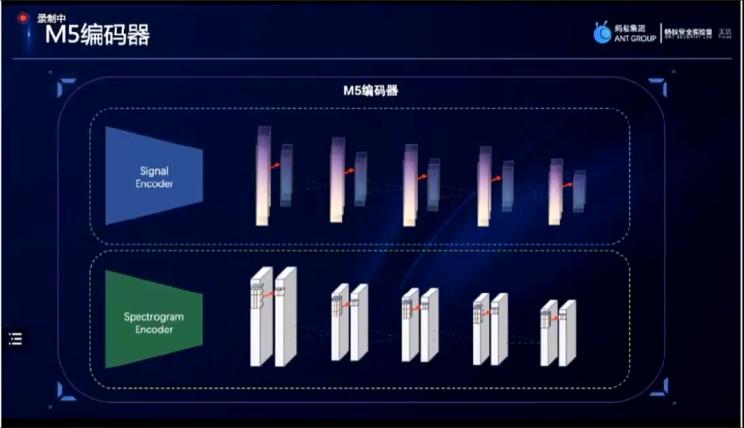
在该编码器的基础上,分享方可做出非常多的训练,如图所示的时域m5编码。在经过baseline处理后,该信号可直接经过小波变化,做一个高频和低频的编码器,最终融合去做分类任务。频域信号也是如此,在经过频域信号处理后,该信号将被直接输送到m5编码器上进行处理。
在简单的浅层网络里面,分享方所设计的编码器也可以设计出网络较深的网络结构。如图所示seresnet编码器,该编码器结构参考了2022年怡个声纹比赛的算法结构,将m5网络替换成一个比较深层的resnet网络结构。
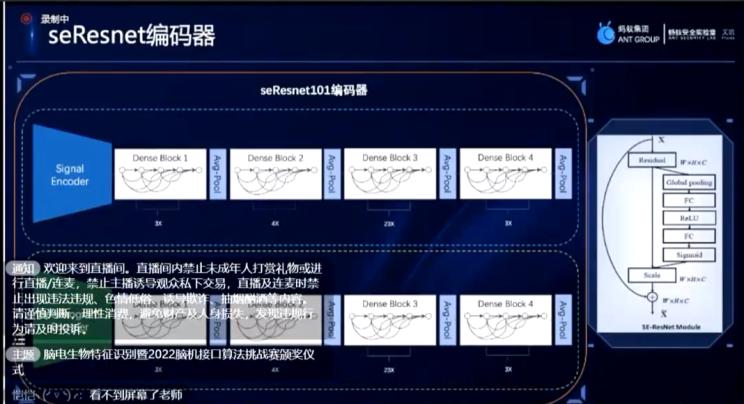
在训练时,分享方也加入了较多的对比学习。在度量学习方面,待信号经过m5编码器处理及各种方式处理后,会将最后一个表征与数据集中不同人自身的信号表征做处理,较为经典的方式是一个“推远拉近”的方式,让属于同一类别的向量越集中,通过度量去“推远”不属于同一类别的特征。
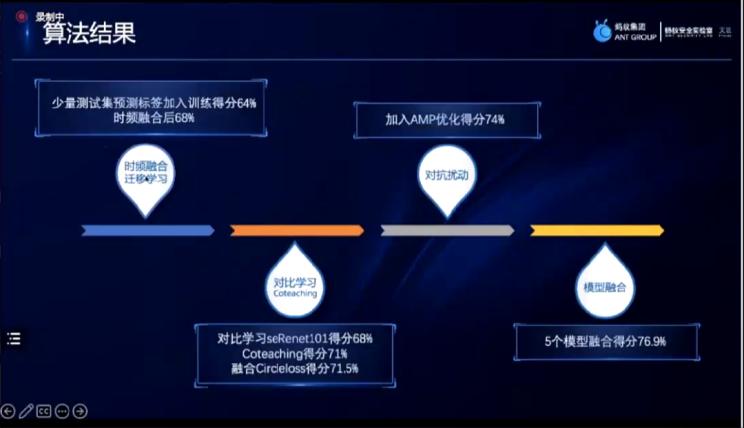
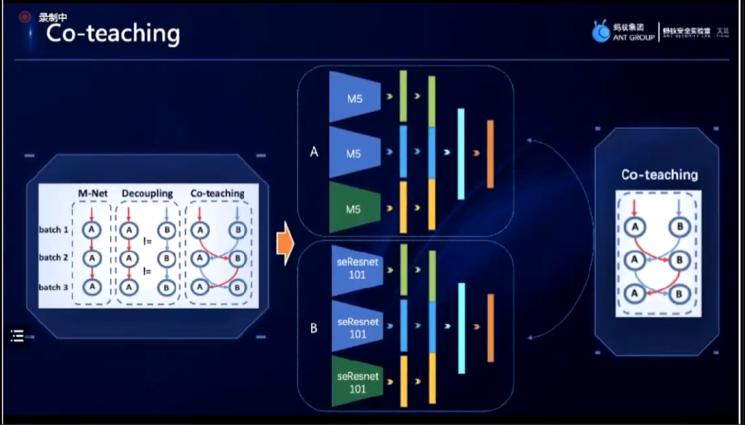
随后,分享方提出了训练集数据良好但测试集数据差异较大的问题,并提出了分享方做出的co-teaching的学习方式。主要思想是通过基础编码器学习到的分类任务,对测试集上的数据进行预测和打伪标签,但这些伪标签是有一定错误的,co-teaching的学习方式就是通过“teacher-student“的方式和这些有一定错误的数据,去学习得出一个具有鲁棒性的模型。
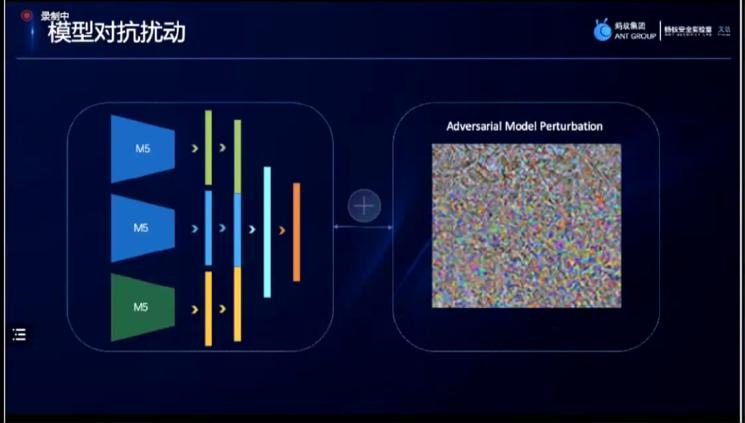
最后一部分是模型对抗扰动,对于脑纹等数据采集时噪声等信号影响较大的问题,使用amp扰动的方法,在模型上加入对抗扰动,在对抗扰动的过程当中去训练学习得出模型。
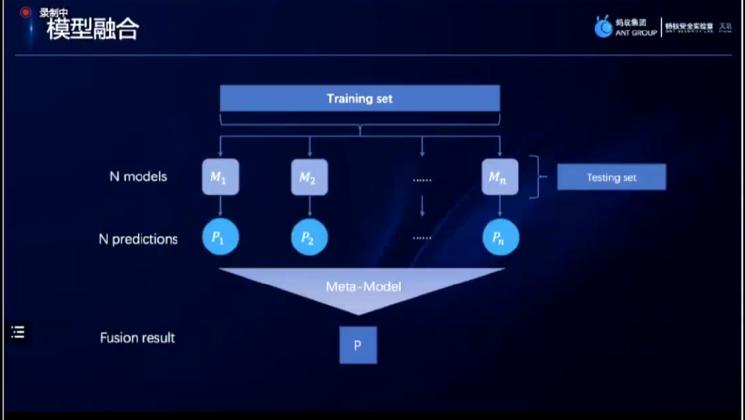
随后分享方通过常用的模型融合方式去对算法进行一个融合。
最后分享方对参赛以来的算法结果进行了总结,并分享了参赛以来的收获和思考,分享方将在未来对于该识别方案所遇到的问题进行更多的挑战。